
计算机系统基础(下)荣誉课程。2021 年春季。
- 实验课时间: 每周一,15:25-17:05 p.m.
- GitHub 仓库: FDUCSLG/ICS-2021Spring-FDU
- 课程首页: https://fducslg.github.io/ICS-2021Spring-FDU/
- 答疑平台: FDUCSLG Slack,#sig-architecture
- 常见问题 / 外部资料 / 仓库结构 / 贡献者
实验课程安排:
| 日期 | 课程安排 | 日期 | 课程安排 |
|---|---|---|---|
| 3.1 |
布置实验 0 布置实验 1 |
4.26 | 布置实验 4 |
| 3.8 | 实验 0 结束 | 5.3 | 五一劳动节 |
| 3.15 | 5.10 |
实验 3 提交 访存优化 |
|
| 3.22 |
实验 1 提交 布置实验 2a |
5.17 |
实验 4 提交 Final Project Topics |
| 3.29 |
发布挑战课题 布置实验 2b |
5.24 | 外设 |
| 4.5 | 清明节 | 5.31 | RAM on FPGA |
| 4.12 |
实验 2 提交 布置实验 3a |
6.7 | 中期报告 |
| 4.19 | 布置实验 3b | 6.14 | 端午节 |
| 期末 | 提交挑战项目 | ||
体系结构部分
本学期体系结构部分的实验将会实现一个 MIPS32 微架构的基础 5 级流水线 CPU,并且将在 FPGA 开发板上进行测试。体系结构部分一共有 4 个需要提交的实验。
- 实验 0:准备开发环境和测试环境。
- 实验 1:基础的五级流水线 MIPS CPU。
- 实验 2:访存仲裁和总线延时(2a)、多周期乘除法器(2b)。
- 实验 3:单周期缓存(cache)。
- 实验 4:MIPS 异常处理。
实验 0:开发环境
这个实验将指导你们准备后续实验的开发环境,并且运行我们提供的标准 CPU 实现(RefCPU),以方便大家熟悉开发和测试的流程。本实验无需提交。
安装 Vivado
本学期的实验要求统一使用 Vivado 2019.2。
Vivado 可以在 Windows 环境和 Linux 环境1下安装。请参见龙芯杯的资料中的 “ A6 - Vivado 安装说明” 来完成 Vivado 的安装。安装完成后,启动 Vivado 后应该能看到类似于下面的窗口:
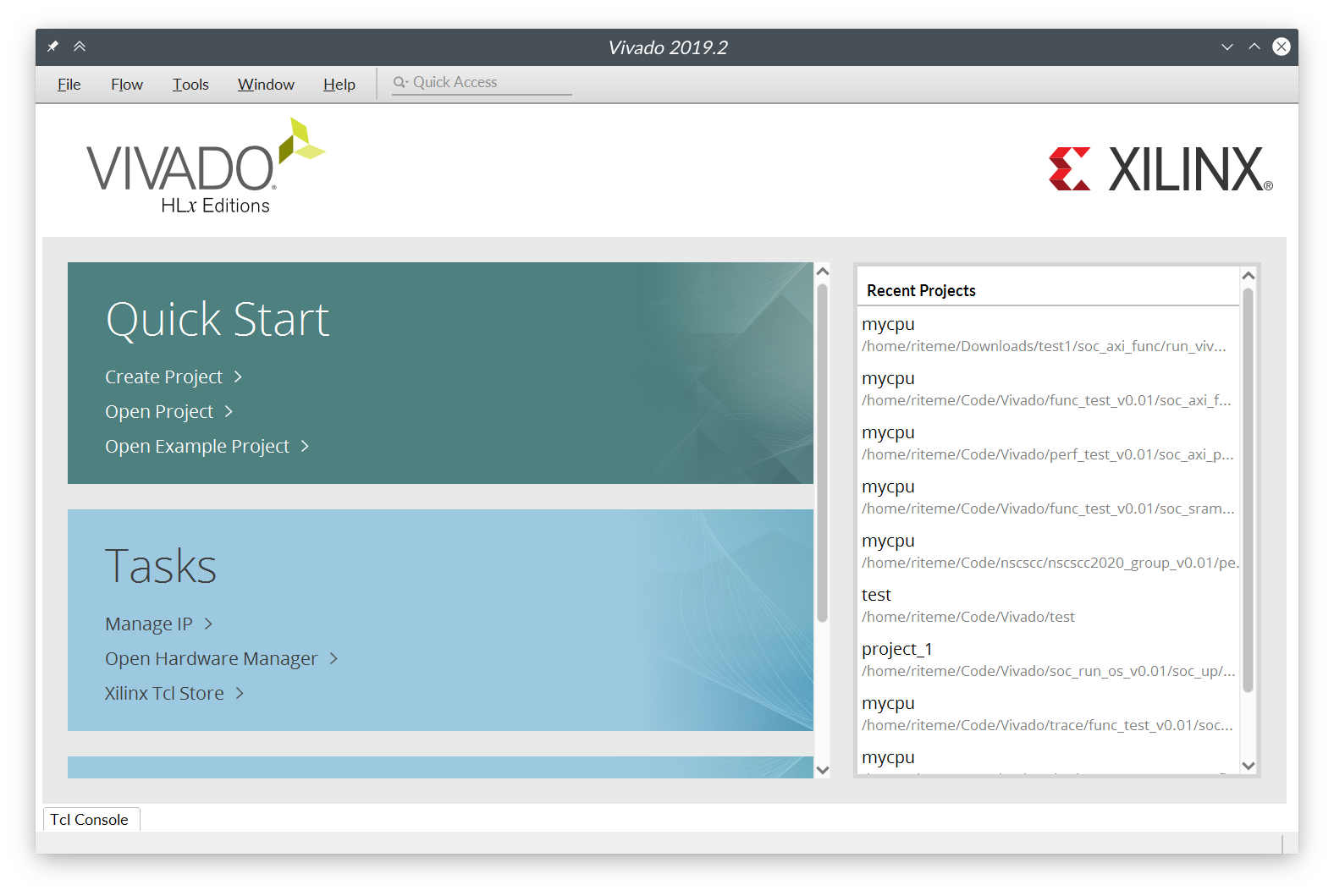
对于 Linux 环境
如果你不想折腾 Vivado 的安装,可以找助教索要打包好的 Vivado 文件 “ xilinx.tar” 来省去下载和安装的步骤。
Linux 下 Vivado 的安装器不会安装 cable driver。我们需要手动安装 cable driver 后才能将 FPGA 开发板连接到 Vivado 上。请在终端中执行下面的命令来安装 cable driver:
export VIVADO_ROOT=/opt/xilinx/Vivado/2019.2
cd $VIVADO_ROOT/data/xicom/cable_drivers/lin64/install_script/install_drivers
sudo ./install_drivers
VIVADO_ROOT 是 Vivado 的安装位置。如果在安装时没有改动安装位置,默认位置是 /opt/xilinx/Vivado/2019.2。
如果你安装完成后找不到 Vivado 的启动项,可以在终端中启动 Vivado:
cd $VIVADO_ROOT
source ./settings64.sh
vivado
此外你可以考虑制作一个桌面启动项。
安装 Verilator
本学期的实验会引入 Verilator 作为 Vivado 外的另一个仿真器。除了 Verilator 本身外,我们还需要一些其它的软件包才能进行完整的仿真和调试的流程。请参考课程的 GitHub 仓库首页的 “ README.md” 中的指示来安装这些软件包。
我们建议你在 Linux 环境下使用 Verilator。我们会保证 Verilator 的测试至少能够在 Ubuntu 20.04 上工作。其它版本的 Linux 的发行版(例如 Ubuntu 18.04、Manjaro、ArchLinux)理论上也是可以无障碍使用 Verilator 仿真的。如果你想在 Windows 上进行实验,我们建议你使用 WSL2 或者运行一个虚拟机。
下载 Git 仓库
本学期的实验将会使用 Git 来做版本管理。你们的所有代码都将放在 Git 仓库中的指定位置,然后通过我们提供的脚本和 Vivado 工程文件(.xpr)来进行仿真和上板测试。因此,你需要在你的系统上安装 Git。想必很多同学都已经接触过 Git 了,因此这里就不再赘述 Git 的安装和配置流程了。
实验内容将在后续陆续放出。为了避免与你的工作 Git 分支有冲突,请避免直接在 master/main 分支以及 lab0、lab1、lab2、... 这些分支上做改动。我们建议你新建一个 dev 分支来编写你的代码:
git checkout -b dev
当有新的实验内容放出时(例如布置了实验 2),将你的 dev 分支 rebase 到新的实验的分支上:
git fetch origin
git checkout dev
git rebase origin/lab2
如果在 rebase 时发生冲突,请阅读 Git 输出的消息,并根据 Git 的指示解决冲突后,再使用 git rebase --continue 恢复 rebase 流程。直到没有冲突产生并且 rebase 完成为止。
RefCPU
在 Git 仓库的 source/refcpu 目录下,有我们提供的标准 CPU(RefCPU)的源代码。RefCPU 是一个多周期 CPU,其可以通过龙芯杯的所有功能测试和性能测试。我们本学期的测试主要是龙芯杯的功能测试和性能测试,因此你可以用 RefCPU 来作为你的流水线 CPU 的对照。当然,我们不能保证 RefCPU 完全没有 BUG。如果 RefCPU 有不符合 MIPS 标准的行为,请以 MIPS 标准为准,并且可以向助教反馈。
接下来将使用 RefCPU 来运行一些测试,方便大家熟悉开发流程。
运行测试 1
在仓库的 vivado 目录下有来自龙芯杯的测试。以测试 1 为例,在 Vivado 中打开文件 vivado/test1/soc_axi_func/run_vivado/mycpu_prj1/mycpu.xpr。然后点击顶部菜单栏的 “Tools” → “Run Tcl Script...”:
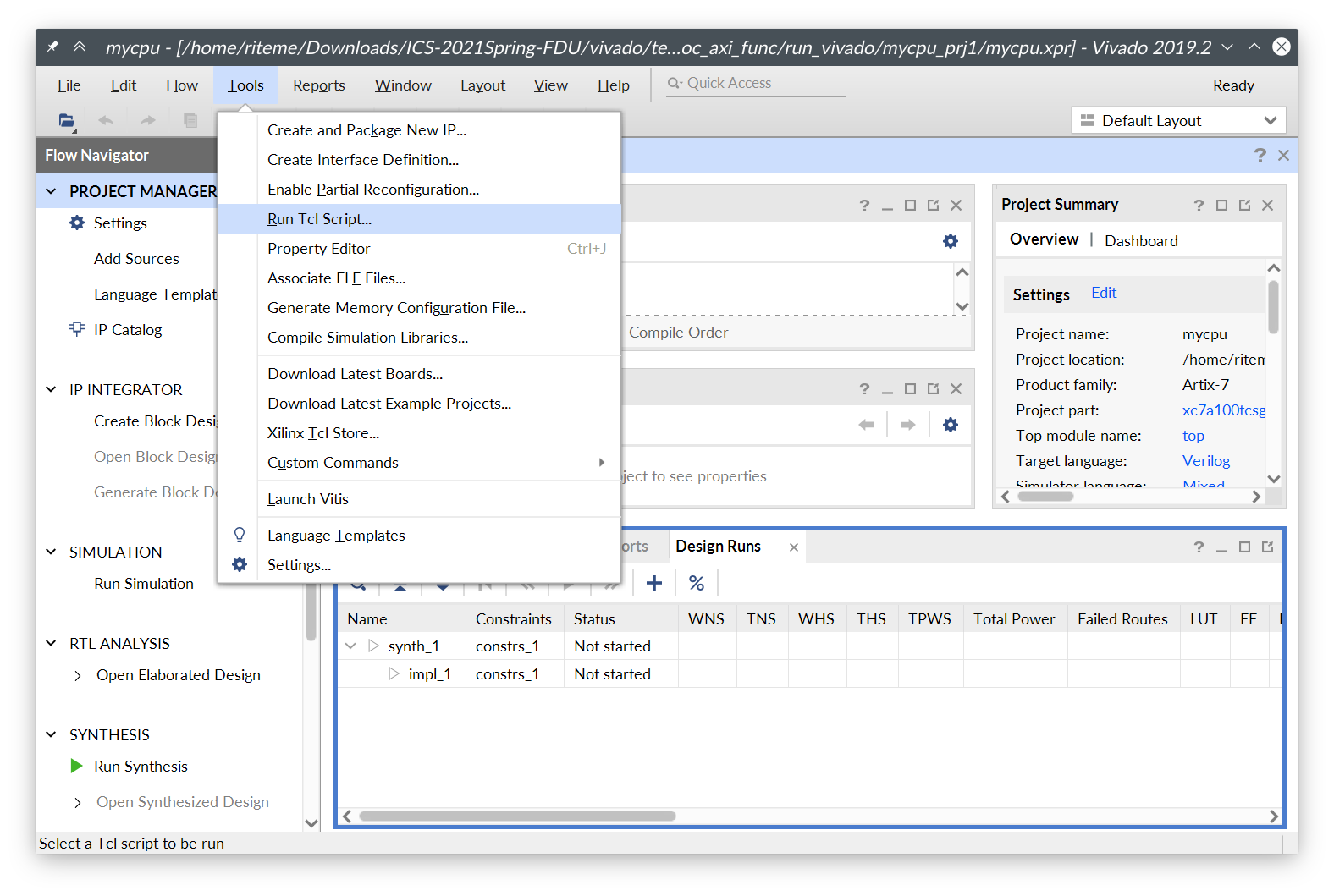
在弹出的对话框中选择 Git 仓库中的文件 source/refcpu/add_sources.tcl。这个 Tcl 脚本会将所有的 RefCPU 的源代码加入到 Vivado 的工程中。你可能注意到 source/mycpu 目录下也有个 add_sources.tcl,这个 Tcl 脚本就是以后加入你自己的 CPU 的源码时会用到的。源码加入后等待 Vivado 处理完成,就能在 “Sources” 窗口里看到新加入的源码/模块:
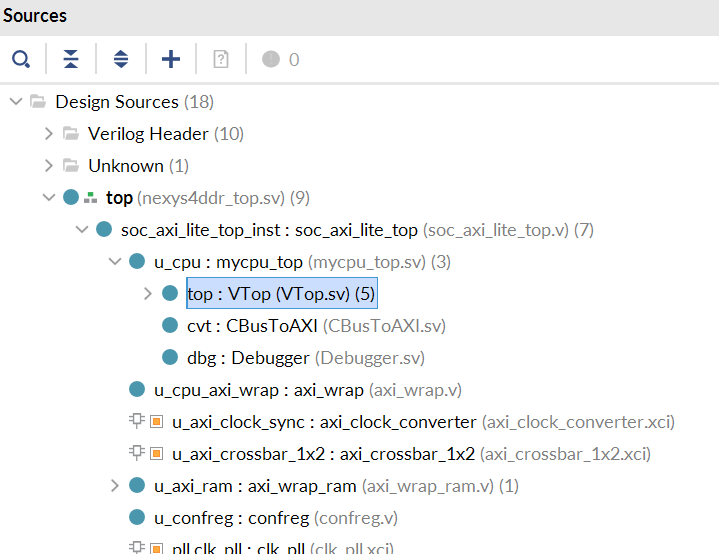
之后在左侧的 “Flow Navigator” 里面点击 “Run Simulation” → “Run Behavioral Simulation” 启动仿真。第一次仿真前因为需要综合 IP 核,所以可能比较慢,需要等待若干分钟才能启动2。之后仿真的启动速度会快很多。
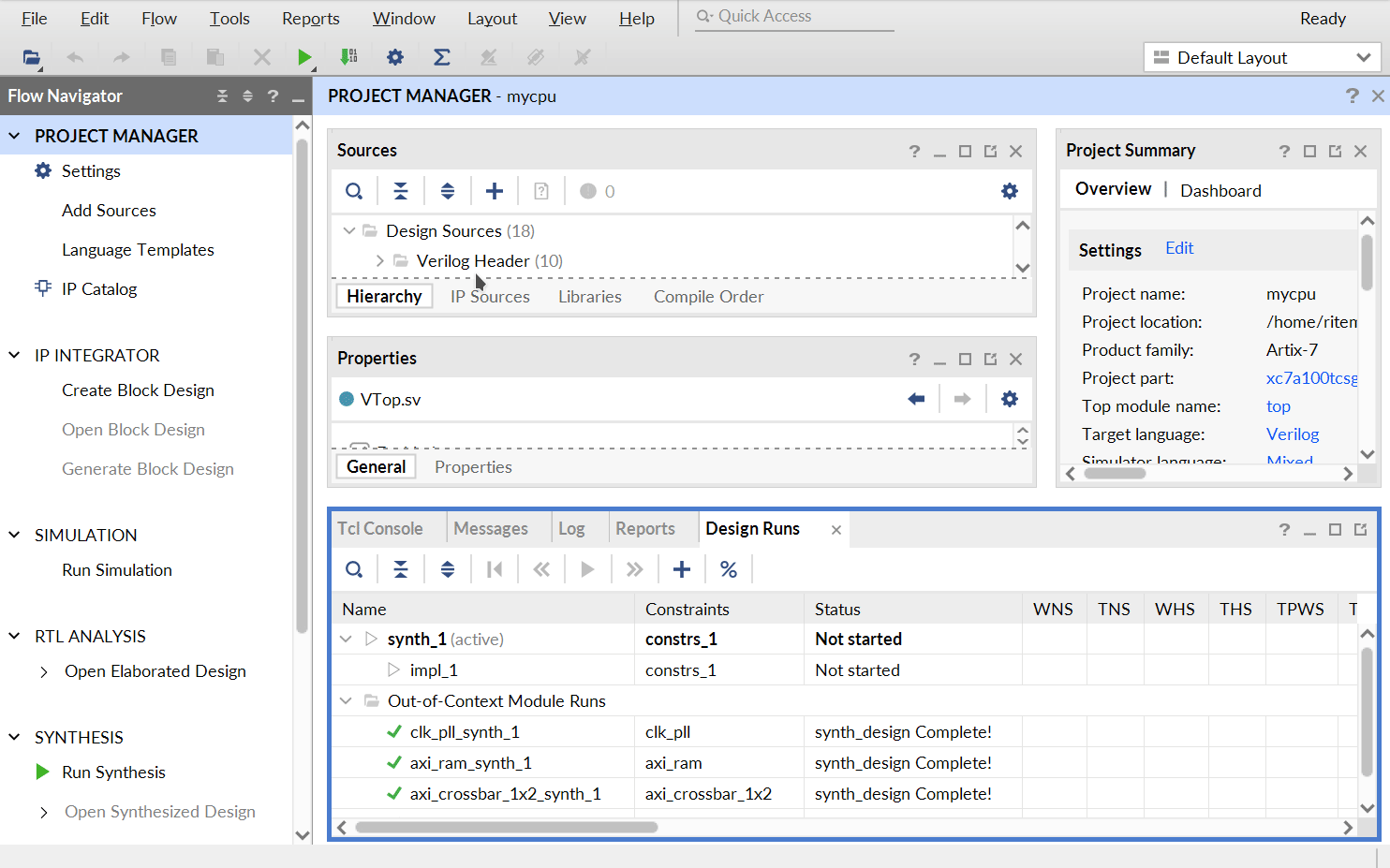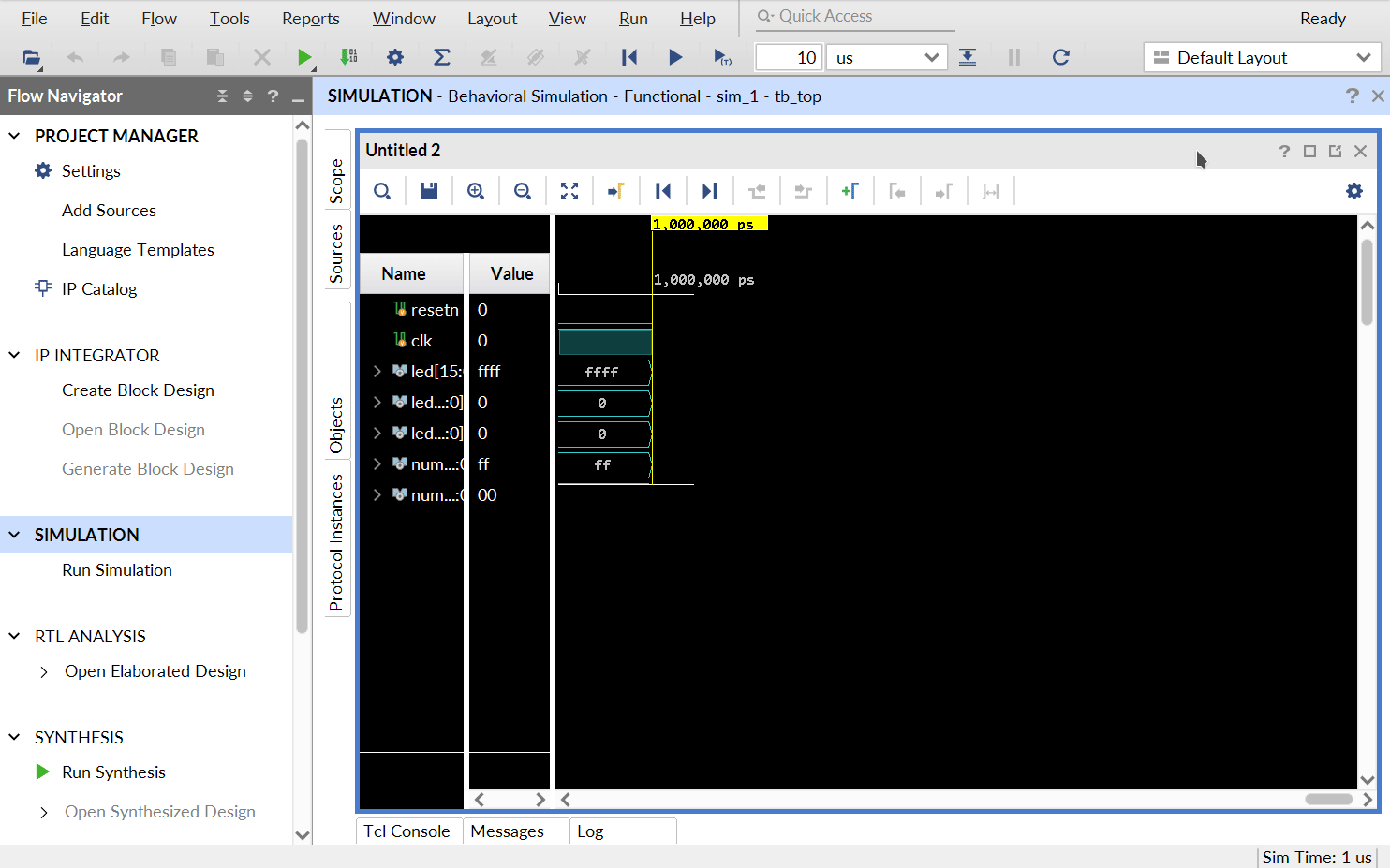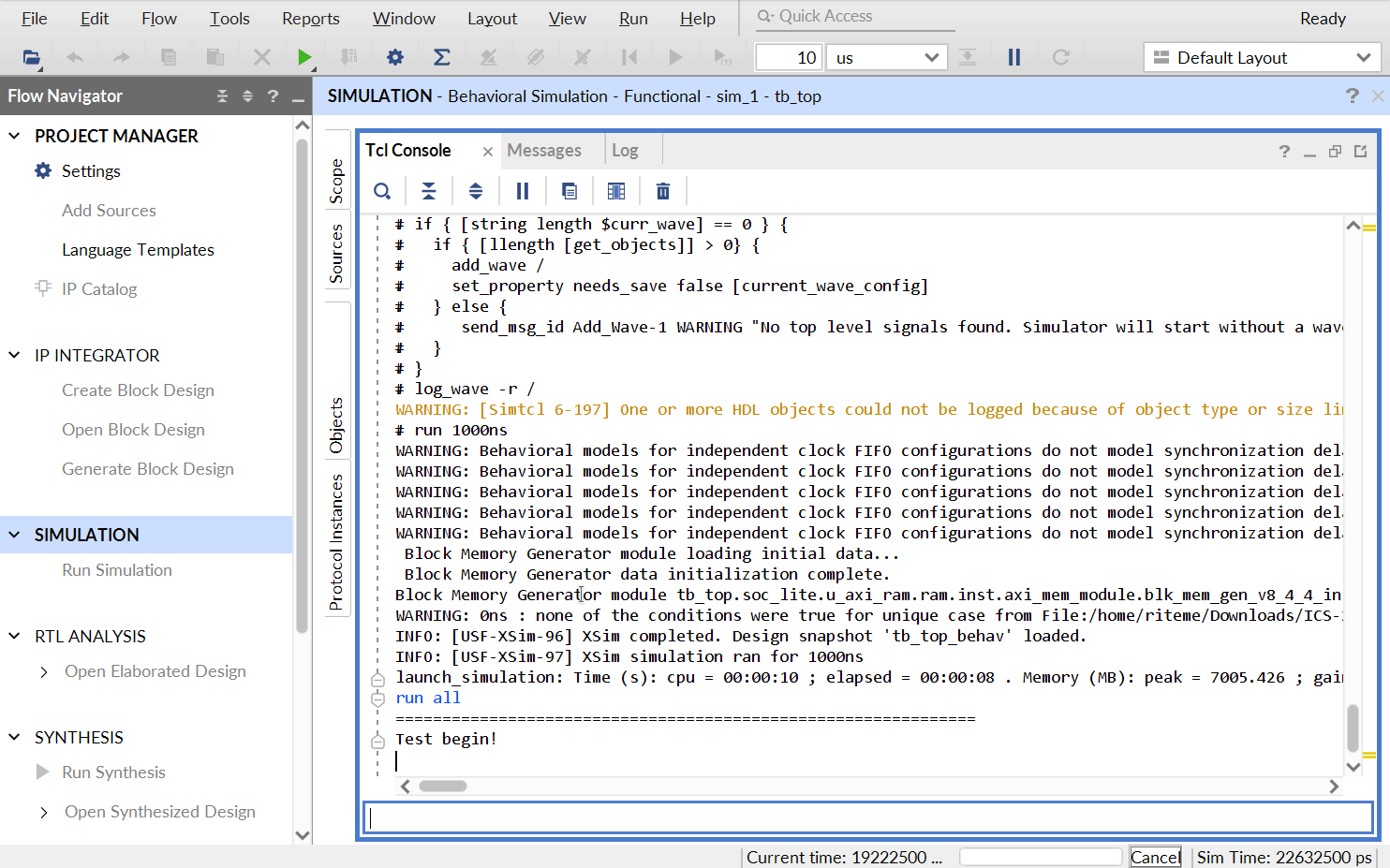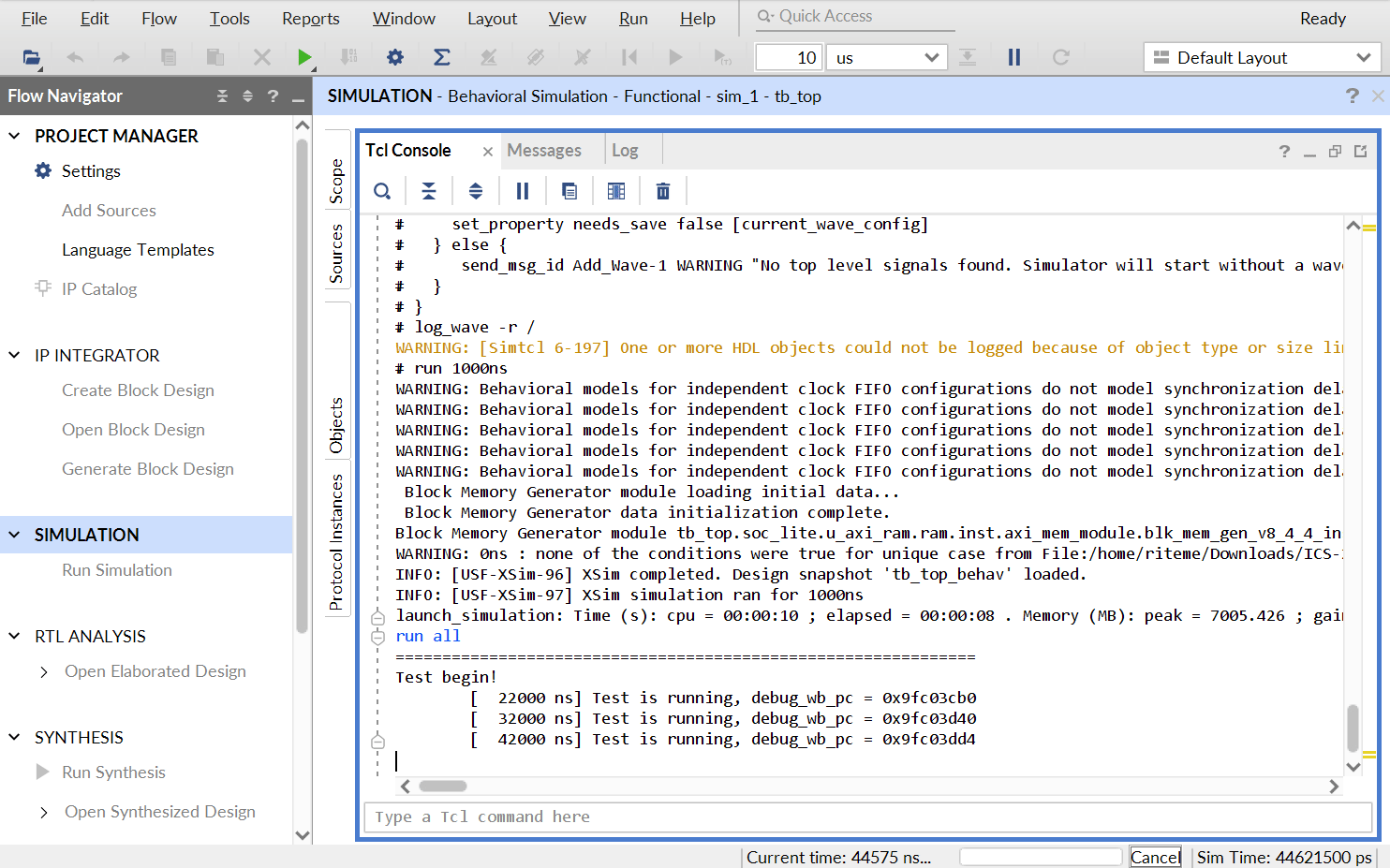
点击界面下侧的 “Tcl Console” 可以看到仿真测试的输出。如果测试通过,最后应该能在这里看到类似于下面的输出:
[17532000 ns] Test is running, debug_wb_pc = 0xbfc100d8
[17542000 ns] Test is running, debug_wb_pc = 0xbfc10178
[17552000 ns] Test is running, debug_wb_pc = 0xbfc10218
[17562000 ns] Test is running, debug_wb_pc = 0xbfc102bc
----[17563425 ns] Number 8'd29 Functional Test Point PASS!!!
[17572000 ns] Test is running, debug_wb_pc = 0xbfc008f4
==============================================================
Test end!
----PASS!!!
$finish called at time : 17579574500 ps : File "/home/riteme/Downloads/ICS-2021Spring-FDU/vivado/test1/soc_axi_func/testbench/mycpu_tb.v" Line 269
run: Time (s): cpu = 00:00:17 ; elapsed = 00:03:32 . Memory (MB): peak = 7061.156 ; gain = 0.000 ; free physical = 3362 ; free virtual = 19061
测试 1 上板
想必你们在上学期已经学习过如何生成比特流文件并且将其烧录到 FPGA 开发板上了。在测试 1 的工程中直接生成比特流,然后上板运行,最终应该能看到下面的效果:

(NOTE:这是一张老图,最新的测试 1 的数码管两侧应该显示 “1c”)
Verilator 仿真
本学期会使用 Verilator 做一些额外的测试。你可以阅读附加资料中的 Verilator 仿真来了解一些基本的注意事项。
首先在 Git 仓库根目录打开一个终端,使用以下命令来用 RefCPU 跑龙芯杯的功能测试:
make vsim -j
最后应该能看到类似于下面的输出:
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: load: ignored unknown destination 0x8ffc.
(info) #77 completed.
(info) #78 completed.
(info) #79 completed.
(info) #80 completed.
(info) #81 completed.
(info) #82 completed.
(info) #83 completed.
(info) #84 completed.
(info) #85 completed.
(info) #86 completed.
(info) #87 completed.
(info) #88 completed.
(info) #89 completed.
(info) testbench finished in 905987 cycles (599.199 KHz).
(warn) TextDiff: 7 error(s) suppressed.
然后用 RefCPU 运行龙芯杯性能测试中的 CoreMark:
make vsim -j VSIM_ARGS='--force-diff -m "./misc/nscscc/coremark.coe" -r "./misc/std/coremark.txt"'
最后应该能看到如下的输出:
./build/gcc/refcpu/VTop/vmain --force-diff -m "./misc/nscscc/coremark.coe" -r "./misc/std/coremark.txt"
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: load: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: store: ignored unknown destination 0x8ffc.
CONFREG: load: ignored unknown destination 0x8ffc.
coremark test begin.
arg : 0, 0, 102, 1, 7, 1, 2000
test start
computation done
2K performance run parameters for coremark.
CoreMark Size : 666
Total ns : 24578460
Iterations/Sec : 40
COREMARK/MHZ = (1000000.0/CPU_COUNT_PER_US)*NSEC_PER_USEC*results[0].iterations/total_ns
It equals to 1000*1000*iteration/total_ns
In this run, iterate=1, total_ns=24578460
Total ticks : 0
Total time (secs): 0
Iterations : 1
Compiler version : GCC4.3.0
Compiler flags :
Memory location : Please put data memory location here
(e.g. code in flash, data on heap etc)
seedcrc : 0xe9f5
[0]crclist : 0xe714
[0]crcmatrix : 0x1fd7
[0]crcstate : 0x8e3a
[0]crcfinal : 0xe714
Correct operation validated. See readme.txt for run and reporting rules.
coremark PASS!
coremark: Total Count(SoC count) = 0x2903e1
coremark: Total Count(CPU count) = 0x290399
(info) testbench finished in 2709066 cycles (612.085 KHz).
使用 GTKWave
Verilator 仿真可以生成 FST 格式的波形图,需要使用一个上古开源软件 GTKWave 来查看。我们提供了 misc/demo.fst 和 misc/demo.gtkw 作为样例波形图文件,供大家体验 GTKWave 的使用。GTKWave 的基本操作请参阅 “使用 GTKWave”。
虽然 Xilinx 官方声明中只支持 Ubuntu,但实际上其它大多数 Linux 发行版都能正常安装和使用 Vivado。
你也可以在 “Sources” 的 “IP Sources” 一栏里面提前生成所有的 IP 核(选中所有 IP 核,右键并点击 “Generate Output Products”)。这样可以同时综合多个 IP 核,速度更快,并且不用综合完就可以仿真。
实验 1:五级流水线 MIPS CPU
先修内容:《深入学习计算机系统》Chapter 4: Pipelined Y86 CPU
1.1 MIPS 微体系结构
五级流水线,属于体系结构的范畴。不同指令集的 CPU,都可以有五级流水线的实现。
指令集是微体系结构的一部分,规范了指令编码等信息。
MIPS 属于精简指令集(Reduced Instruction Set Computing,RISC)。我们需要实现的 MIPS,部分基本信息如下:
- 每条指令长度为 4 字节(32 位)。
- 32 个通用寄存器,每个寄存器 32 位。0 号寄存器只读恒为 0。
- 内存读写的最小单位为 1 字节(8 位)。
1.1.1 MIPS 指令集
详见 MIPS 手册 Ⅱ: Volume II: MIPS32 Instruction Set。
这里介绍一下本实验中将要实现的部分指令:
01ae5821 addu t3,t5,t6
| [31:26]:000000 | [25:21]:01101 | [20:16]:01110 | [15:11]:01011 | [10:6]:00000 | [5:0]:100001 |
|---|---|---|---|---|---|
| 指令类型:寄存器类型 | rs: t5 | rt: t6 | rd: t3 | 全 0 | ADDU |
操作:Reg[rd] ← Reg[rs] + Reg[rt]
25290001 addiu t1,t1,1
| [31:26]:001001 | [25:21]:01001 | [21:16]:01001 | [15:0]:0000_0000_0000_0001 |
|---|---|---|---|
| 指令类型:ADDIU | rs: t1 | rt: t1 | 立即数 immediate |
操作:Reg[rt] = Reg[rs] + Sign_Extend(immediate)
注意:该指令中的 u 表示寄存器为无符号的,是为了忽略溢出(和 C 语言的 int、unsigned 加法语义一致),立即数仍需符号位扩展。有一部分指令的立即数是 0 扩展。
8d0c0000 lw t4,0(t0)
| [31:26]:100011 | [25:21]:01000 | [20:16]:01100 | [15:0]:0000_0000_0000_0000 |
|---|---|---|---|
| 指令类型:LW | base: t0 | rt: t4 | offset |
操作:
vaddr ← Reg[base] + Sign_Extend(offset)if (vaddr[1:0] != 2'b0) Exception(Address Exception)(本实验中,可以保证vaddr是 4 字节对齐)Reg[rt] ← LoadMemory(AddressTranslation(vaddr), size = WORD)
pc = bfc00704: 0ff00f00 jal bfc03c00 <n1_lui_test>
| [31:26]:000011 | [25:0]:11_1111_0000_0000_1111_0000_0000 |
|---|---|
| 指令类型:JAL(jump and link) | instr_index |
操作:
Reg[31] ← pc + 8- 执行下一条指令时:
pc ← {pc[31:28], instr_index, 2'b00}
JAL 指令常用于函数调用。
# note: in MIPS, branch-type instructions (including j, beq) have a delay slot.
sample1:
beq zero, zero, here # branch if equal
instruction1
instruction2
here:
instruction3
# sequence is: beq -> instruction1 -> instruction3
sample2:
bne zero, zero, there # branch if not equal
instruction 4
instruction 5
instruction 6
there:
instruction 7
# sequence is: bne -> instruction 4 -> instruction 5
本实验需要实现的指令:lui、addu、addiu、beq、bne、lw、or、slt、slti、sltiu、sll、sw、j、jal、jr、addisubu、sltu、and、andi、nor、ori、xor、xori、sra、srl、jalr
1.1.2 虚实地址转换
指令代码、寄存器中的地址都是虚拟地址。CPU 向内存请求时,需要提供物理地址。
本实验中,只要求实现简单的虚实地址转换。
typedef logic [31:0] paddr_t;
typedef logic [31:0] vaddr_t;
paddr_t paddr; // physical address
vaddr_t vaddr; // virtual address
assign paddr[27:0] = vaddr[27:0];
always_comb begin
unique case (vaddr[31:28])
4'h8: paddr[31:28] = 4'b0; // kseg0
4'h9: paddr[31:28] = 4'b1; // kseg0
4'ha: paddr[31:28] = 4'b0; // kseg1
4'hb: paddr[31:28] = 4'b1; // kseg1
default: paddr[31:28] = vaddr[31:28]; // useg, ksseg, kseg3
endcase
end
亦可以参考 RefCPU 中模块 AddressTranslator 的实现。
例如,当指令访问地址 0xbfc00380 时,实际访问的物理地址应该是 0x1fc00380。详见 MIPS 手册 Ⅲ: Volume III: MIPS32 Privileged Resource Architecture,第 29 页。
1.2 五级流水线
五级流水线的简单示意图如下:
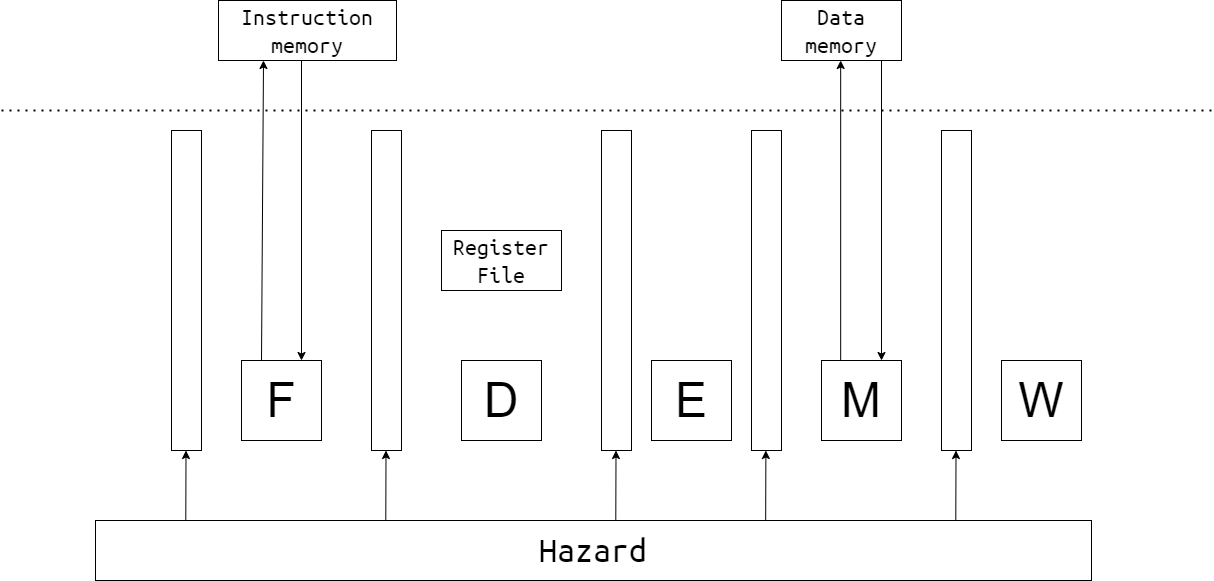
虚线上方为内存部分的硬件,由测试文件提供。
写 CPU,就是实现 CPU 的内部,并用事先定好的接口进行封装。
1.2.1 Select PC
这一阶段在 Fetch Pipeline Register 前,选择流水线所执行的下一条指令的 PC。
可能的来源:
- 顺序的下一条指令(PC + 4)
- jump 类指令(
{pc[31:28], instr_index, 2'b00})
等等。
1.2.2 Fetch
向 Instruction Memory 提供指令地址,并接收指令。
注意:本实验中,内存有 1 周期的固定延迟。
其行为类似于:
logic [127:0][31:0] memory;
logic [6:0] addr;
logic [31:0] data;
always_ff @(posedge clk) begin
data <= memory[addr];
end
可考虑把接受的数据直接接到下一流水段。
1.2.3 Decode
D 阶段完成:
- 指令解码,生成控制信号
- 从 Regfile(寄存器文件堆)中读取数据
- 判断是否跳转
1.2.4 Execute
E 阶段主要为 ALU。
1.2.5 Memory
M 阶段向 Data Memory 提供数据地址,并接收数据。
注意:本实验中,内存有 1 周期固定延迟。
1.2.6 Writeback
W 阶段向 Regfile 写数据。
1.2.7 Regfile
根据 MIPS 指令集架构,每条指令最多写 1 个通用寄存器,最多读 2 个通用寄存器。所以 Regfile 应设计为 1 个写端口,2 个读端口。
参考代码:
typedef logic[31:0] word_t;
typedef logic[4:0] creg_addr_t;
module regfile(
input logic clk,
input creg_addr_t ra1, ra2, wa3,
input logic write_enable,
input word_t wd3
output word_t rd1, rd2
);
word_t [31:1] regs, regs_nxt;
// write: sequential logic
always_ff @(posedge clk) begin
regs[31:1] <= regs_nxt[31:1];
end
for (genvar i = 1; i <= 31; i ++) begin
always_comb begin
regs_nxt[i[4:0]] = regs[i[4:0]];
if (wa3 == i[4:0] && write_enable) begin
regs_nxt[i[4:0]] = wd3;
end
end
end
// read: combinational logic
assign rd1 = (ra1 == 5'b0) ? '0 : regs[ra1]; // or regs_nxt[ra1] ?
assign rd2 = (ra2 == 5'b0) ? '0 : regs[ra2];
endmodule
1.2.8 Pipeline register
五级流水线中,会有阻塞与气泡,所以流水线寄存器需要提供这些机制。
参考代码:
typedef struct packed {
logic a;
} fetch_data_t;
module dreg (
input logic clk, resetn,
input fetch_data_t dataF_new,
input logic enable, flush,
output fetch_data_t dataF
);
always_ff @(posedge clk) begin
if (~resetn | flush) begin // flush overrides enable
dataF <= '0;
end else if (enable) begin
dataF <= dataF_new;
end
end
endmodule
Tips:
- W 阶段流水线寄存器不允许被阻塞。
- F 阶段流水线寄存器一般不清零;PC的复位值为
32'hbfc0_0000。 - M 阶段流水线寄存器阻塞时(因),E 阶段流水线寄存器通常也阻塞(果),防止丢失指令。
- E 阶段流水线寄存器阻塞时(因),M 阶段流水线寄存器通常清零(果),防止指令被执行多次。
1.2.9 Hazard and Forward
这个部分代码量可能不大,但应该是本实验中最复杂的部分。
主要难点是数据冲突。本实验中,仅需考虑写后读(RAW)冲突。请思考:
- 冲突阻塞部分:D 阶段取数据,E、M、W 阶段的写数据会造成冲突。哪些情况应当阻塞流水线?
- 转发部分:哪些指令写通用寄存器?电路图中的哪些数据线可作为转发来源?转发条件是什么?优先级是什么?
分支预测失败的情况比较简单。D 阶段判断分支是否跳转;由于 delay slot 的设计,F 阶段的指令一定执行。所以,分支跳转不会有额外的惩罚(数据冲突可能存在)。
1.2.10 封装 CPU
本实验的 CPU 的最顶层封装为 SRAM 接口。见 source/mycpu/mycpu_top.sv。
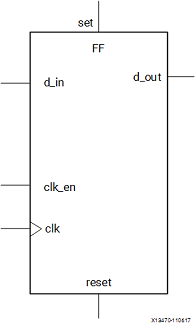
module mycpu_top (
input logic clk,
input logic resetn, // low active
input logic[5:0] ext_int, // interrupt, high active
output logic inst_sram_en, // 指令内存总使能
output logic[3:0] inst_sram_wen, // 字节写使能,本实验中为全 0
output logic[31:0] inst_sram_addr, // 地址
output logic[31:0] inst_sram_wdata, // 写数据
input logic[31:0] inst_sram_rdata, // 读数据
output logic data_sram_en, // 数据内存总使能
output logic[3:0] data_sram_wen, // 字节写使能,本实验中为全 0 或全 1
output logic[31:0] data_sram_addr, // 地址
output logic[31:0] data_sram_wdata, // 写数据
input logic[31:0] data_sram_rdata, // 读数据
//debug
output logic[31:0] debug_wb_pc, // W 阶段 PC
output logic[3:0] debug_wb_rf_wen, // 写使能,一般为全 0 或全 1
output logic[4:0] debug_wb_rf_wnum, // 写入的寄存器
output logic[31:0] debug_wb_rf_wdata // 写回的数据
);
// TODO: other circuit
endmodule
为了保证和后续实验在接口上的统一,我们在 CPU 内部统一使用 DBus 接口。在 source/mycpu/SRAMTop.sv 做了从 DBus 接口到类 SRAM 接口的转换。DBus 接口定义在 source/include/common.svh 中:
typedef struct packed {
logic valid; // 是否有请求?
addr_t addr; // 请求读写的地址
msize_t size; // 读写数据的大小:1、2 或者 4 字节,分别对应 MSIZE1、MSIZE2 和 MSIZE4
strobe_t strobe; // 4 位的字节写使能信号
word_t data; // 如果写使能不为全 0,这里放写入的数据
} dbus_req_t;
typedef struct packed {
logic addr_ok; // 内存是否已经接收了地址?
logic data_ok; // 内存是否完成了访存?
word_t data; // 请求地址处读出的数据
} dbus_resp_t;
对于本次实验,因为访存是固定延时,并且所有读写的数据以及指令访存都是 4 字节的,所以
dbus_resp_t中的addr_ok和data_ok信号实际上可以忽略。addr最低两位应该始终为 0,即地址与 4 字节对齐。size始终为MSIZE4。- 写操作时
strobe为4'b1111或4'hf。
你可能会注意到还有一个 IBus 接口。IBus 接口是 DBus 接口的子集,只保留了读取数据所需要的信号。此外,你的流水线部分的顶层模块文件应该是 source/mycpu/MyCore.sv。我们建议你将你的流水线分为多个模块来实现。你可以在 source/mycpu 这个目录下新建文件或者子目录。
你可以选择在模块 SRAMTop 中做地址翻译,或是在模块 MyCore 中做地址翻译。
1.2.11 连接 debug_* 信号
龙芯杯的测试会进行 trace 的比对。这需要从你的流水线中读取一些数据。我们在 1.2.10 一节中已经看到 mycpu_top 最后有四个 debug_* 信号了。为了避免增加下层模块的接口,我们建议你使用跨模块引用来连接这些 debug_* 信号。例如:
// in mycpu_top.sv
assign debug_wb_pc = top.core.writeback.pc;
assign debug_wb_rf_wen = top.core.writeback.aha ? 4'b1111 : 4'b0;
1.3 数据通路与译码控制信号
CPU 需要一系列硬件来执行指令所要求的功能。如果 CPU 只支持一条指令,那么 CPU 内所有的硬件都只为这一个功能所服务。随着指令条数的增加, CPU 设计者会添加一些硬件,同时也会复用一些原有的硬件。随着这些硬件复用性的提升, CPU 的数据通路会变得更复杂。Decode 阶段的译码器为这些硬件提供控制信号,这些控制信号也是高度复用的。
我们设计的第一条指令是 addu。只支持这一条指令的流水线,是比较简单的:

随后,我们加入了 addiu。Execute 阶段的加法器可以被复用,但源操作数不再是两个寄存器的值,而是一个寄存器和一个立即数;目的寄存器也不再是 rd, 而是 rt:

lw 指令通过一个加法器算出数据的虚拟地址,这个加法器可以使用已有的加法器。然而,写入寄存器的数据不再是加法器,而是数据内存:

添加了 jal 指令后,下一条指令的 PC 不再只可能是 (PC + 4);写入的寄存器被指定为 31 号寄存器,数据则是指定为 (PC + 8):

当 CPU 需要支持新的指令时,根据该指令的功能,设计数据通路,并视具体情形添加或复用硬件与控制信号。添加硬件,会增加 CPU 的电路面积;复用原有硬件,会增加复用器的电路复杂性,增加电路延迟。
添加新硬件时,需考虑将该硬件放在流水线的哪一阶段,避免影响该流水段的逻辑延迟。
1.4 *流水线性能评估
在本次实验中,我们实现了五级流水线 CPU。相对于单周期 CPU,流水线 CPU 牺牲了一些 IPC(流水线的数据冲突会阻塞流水线),换取频率的大幅提升。这一节主要分析流水线的性能。
1.4.1 高延迟的逻辑部件
在本实验设计的 CPU 中,有以下几个高延迟的逻辑部件:
寄存器文件:它的读逻辑和写逻辑都十分复杂。读过程的每一位是一个 32 选 1 的复用器,也就是 37 个变量的组合逻辑方程;读数据为 32 位,相当于上述逻辑复制 32 份。1 位寄存器的写逻辑比较简单,但 32 位的写入需要将该逻辑复制 32 次,电路就变得复杂了。
算术逻辑单元 ALU:本实验需要实现的算数操作中,加法、比较运算的电路是级联,移位运算的电路是复用器;整个 ALU 的输出还需要一次复用。
内存:本实验中不需要实现内存,但它在 CPU 的外部,数据传进来有很高的接线延迟。
1.4.2 用转发来减少阻塞
在流水线中,写后读冲突会导致流水线阻塞。
如果需要的寄存器数据,在流水线的其他阶段已经计算好了,可以进行转发。
然而,转发会导致该阶段延迟的增加。下图的转发会大幅度增加 E 阶段的延迟:

1.4.3 Pipeline as Mechanism
单周期 CPU 中,时钟频率是不可控的:为了支持新的指令,需要向数据通路中添加新的逻辑部件,导致延迟将越来越高。
流水线是拆分数据通路的一种机制,它将各个高延迟的逻辑部件划分在不同的流水段,使得电路延迟变得可控。五级流水线是一种策略。根据现有的数据通路和频率要求,设计更深或更浅的流水线。
1.5 发布包
用 Vivado 2019.2 打开 vivado/test1_naive/soc_sram_func/run_vivado/mycpu_prj1/mycpu.xpr,添加源文件后,即可开始仿真。
Tips:第一次仿真前,先点击 “IP Sources”,选中所有 IP 核源文件,右键,点击 “Generate Output Products”。几秒钟后,跳出 “OK”,然后再点仿真。
vivado/test1_naive/soft/obj/test.s 是测试的反汇编文件,有 PC、机器码、汇编码的对应。soft 目录下的其他文件里,可以找到测试的 C 代码。
source/mycpu/ 里已经有一些代码,其中:
mycpu_top.sv是顶层封装文件,仅需把 debug 信号连接上。SRAMTop.sv是 SRAM 接口封装文件,需要添加虚实地址翻译。MyCore.sv是 CPU 主体流水线文件。
你可以在该目录下随意添加源文件。在 Vivado 中执行 add_sources.tcl 后,它们都会添加到项目里。
source/include/ 里有一些头文件。
本次实验没有暂时没有使用 Verilator 进行仿真。我们会从实验 2 开始引入 Verilator,所以你需要确保你的在这次实验中编写的代码能够通过 Verilator 的编译。如果在使用 Verilator 中遇到了问题,请先阅读 Verilator 仿真寻找解决方案。
1.6 作业与提交
在 source/mycpu/ 里添加你的代码,实现五级流水线 MIPS CPU。
本实验需要实现的指令:lui、addu、addiu、beq、bne、lw、or、slt、slti、sltiu、sll、sw、j、jal、jr、addisubu、sltu、and、andi、nor、ori、xor、xori、sra、srl、jalr
PC的复位值为 32'hbfc0_0000。
1.6.1 通过标准
- 打开原有
mycpu.xpr,用source/mycpu/add_sources.tcl添加源文件,上板显示两个绿灯。 - 在仓库根目录打开终端,运行
make verilate TARGET=mycpu/VTop,确认 Verilator 能够编译你的 CPU 代码,并且没有报告任何错误和警告。
1.6.2 实验报告要求
- 格式:PDF
- 内容:按本文档 1.2 节的思路写即可。写好姓名学号。
1.6.3 提交文件格式
18307130024/
├── report/(报告所在目录)
└── source/(源文件所在目录)
用 zip -r 18307130024.zip 18307130024/ 打包。用 unzip 18307130024.zip 检查,应在当前目录下有学号目录。
1.6.4 评分
代码 80%,报告 20%。
Deadline:2021 年 3 月 21 日 23:59:59
1.7 *思考
- 流水线寄存器的 flush 信号,需要让所有信号都清零吗?
- 转发的成本是什么?有哪些限制?(板子上的组合逻辑基本部件为 LUT6,6 输入 1 输出,可实现 6 输入的任何给定逻辑式)
- 不同指令需要用到的流水线阶段可能不同:加法指令似乎不需要经过 Memory 阶段。能让它跳过 M 阶段吗?
实验 2a:总线仲裁与延时
仲裁
多个独立运行的实体同时访问共享资源时,往往需要通过仲裁决定访问的先后顺序。
在实验 1 中,CPU 有两套访存接口:一个用于取指,另一个用于读写数据。test1_naive 将指令内存和数据内存分开了,从而能够同时支持两边的访问。现实生活中的计算机架构一般遵循 von Neumann 架构,即指令和数据放在同一个内存中。此时需要内存有两个读写端口。
但是多端口的存储单元往往非常消耗资源(例如,6 端口寄存器文件)。现代的 CPU 的核心数量越来越多,提供多端口的存储单元非常不现实。此外,如果有两个或者更多的端口同时写入同一个位置时,我们需要规定谁的写入是有效的,此时发生了写入冲突。
解决这一问题的一种方法是仲裁,即当有多个实体同时访问同一个对象时,允许其中一个进行访问,要求其它的实体等待。这个过程类似于加锁互斥。
test1~test4 的内存都只有一个端口,因此需要进行仲裁。
延时
仲裁会导致等待,因此我们不能再期望数据会在固定的时间内返回。此外,现代 CPU 的主频和内存频率往往不同,并且 CPU 为了降低功耗通常会动态调频,因此增加了访存需要的周期数的不确定性。下表是 Intel 的 Skylake 架构中 cache 的各项参数,来自 “Intel 64 and IA-32 Architectures Optimization Reference Manual”:
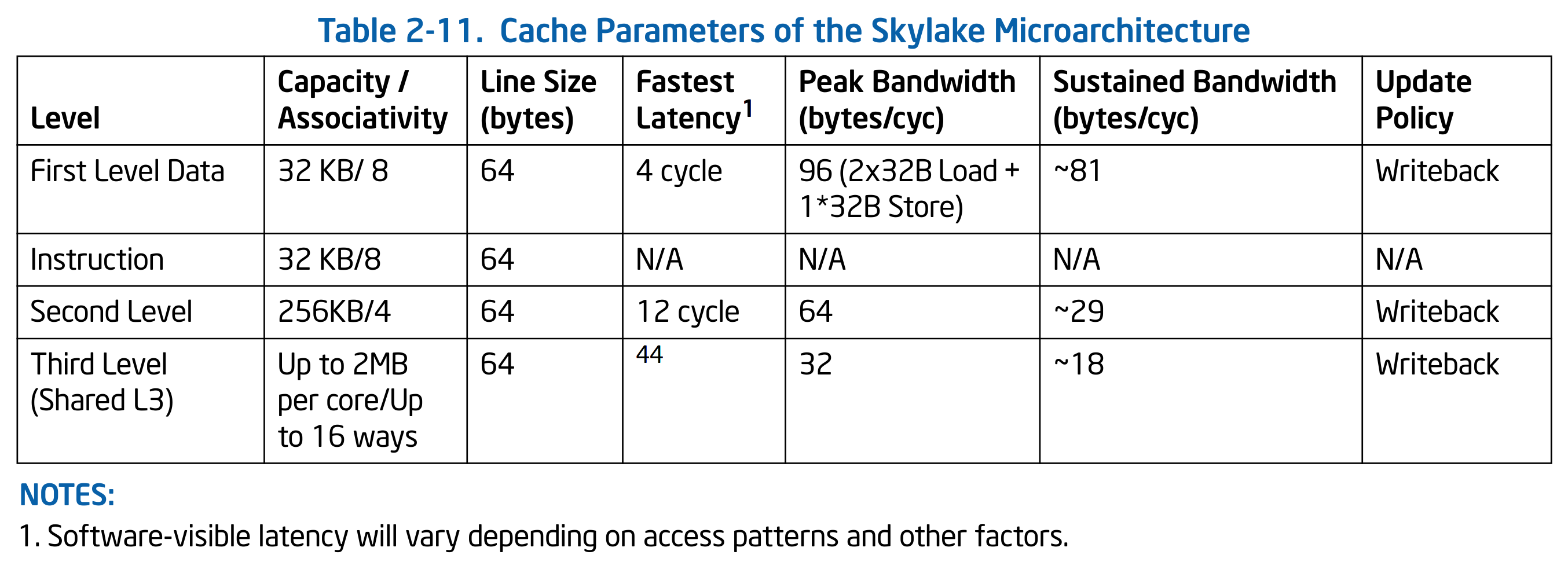
可以看到各级缓存的访问所需要的周期数都是不一样的,并且都不是固定的。
DBus
DBus 是一个单向握手协议,其定义在 common.svh 中:
typedef struct packed {
logic valid; // in request?
addr_t addr; // target address
msize_t size; // number of bytes
strobe_t strobe; // which bytes are enabled? set to zeros for read request
word_t data; // the data to write
} dbus_req_t;
typedef struct packed {
logic addr_ok; // is the address accepted by cache?
logic data_ok; // is the field "data" valid?
word_t data; // the data read from cache
} dbus_resp_t;
总线握手
DBus 的逻辑是:由 CPU 主动发出请求(拉起 valid 信号),等待内存给出反馈(addr_ok 和 data_ok)。DBus 的反馈分为两个阶段,一是内存已经得知并且缓存了 CPU 的请求,此时内存会将 addr_ok 拉起;二是内存已经完成了 CPU 的请求,此时将 data_ok 拉起。这两个过程就是所谓的 “握手”。握手是一个时序逻辑。每当时钟周期上升沿触发时,如果 addr_ok 为 1,表明握手成功。data_ok 同理。例如,CPU 想写入内存,内存也支持单周期写入,此时内存会把 addr_ok 和 data_ok 同时设为 1。等到时钟上升沿到达时,内存就会触发写入,同时 CPU 也知道内存已经完成这个写入了。

如果内存需要多个周期才能完成一次访存,CPU 需要一直拉起 valid 信号,直到内存的 addr_ok 响应。

访存有一个常见的优化是写缓冲区(store buffer)。写缓冲会保存收到的请求,发出 addr_ok,然后再进行真正的写内存操作。CPU 一般不用关心写操作是否真的完成了,因此流水线在收到 addr_ok 的时候就可以继续推进。这样可以明显减少写内存带来的流水线阻塞。

访存也可以切分流水线。CPU 的 fetch 阶段和 memory 阶段可以分为多个周期完成,此时需要 cache 也按照流水线的方式工作。这样即便单次访存的延时很高,cache 提供的吞吐率却不低。

注意:CPU 收到 addr_ok 后,如果没有其它请求,必须把 valid 撤下。
size 信号
size 是一个枚举。DBus 支持 MSIZE1(单字节)、MSIZE2(双字节)和 MSIZE4(四字节)三种模式。
Byte Lanes
DBus 是 32 位的总线,每周期至多传输 4 个字节。data 的四个字节可以视作四个独立的通道 lane[3:0],lane[0] 对应地址最后两位为 2'b00 的那个字节,lane[1] 对应最后两位为 2'b01 的字节,依次类推。因此,无论我们给出的地址是否与 4 字节对齐,data 中的数据依然会按照 4 字节对齐的方式摆放。DBus 提供一个 4 位的写使能 strobe[3:0],strobe[0] 表示 lane[0] 是否启用,strobe[3..1] 类似。通过这种方式,DBus 允许写入比 4 字节窄的数据。
例如,我们向地址 0xbfc001f2 写入单个字节的数据 0xcd 时,由于地址的最低两位为 0x2(2'b10),所以我们应该:
- 地址
addr依然是32'hbfc001f2。 - 将
data设置为32'h00cd0000。 - 将
strobe设置为4'b0100。
这么做可能比较反直觉。DBus 的 byte lanes 来源于 AXI 总线协议,其意图在于兼容只能 4 字节对齐寻址的设备(一般的内存都是这么做的),同时不要求 addr 必须与 4 字节对齐是因为可能会和只能字节寻址的设备交互(例如字符打印)。
换句话说,当你向 0x1f2 发送读取请求时,DBus 会把 0x1f0、0x1f1、0x1f2 和 0x1f3 这四个地址对应的字节全部返回给你,分别放在 data[7:0]、data[15:8]、data[23:16] 和 data[31:24] 中。同样的,当你向 0x1f2 这个地址写入时,实际上是同时向 0x1f0、0x1f1、0x1f2 和 0x1f3 这四个地址对应的字节写入,不过此时我们可以使用 strobe 信号单独决定每个字节是否真的需要写入。
下面展示了从地址 0xbfc01fc2 开始连续写入 15 个字节 0x11~0xff 的过程:

IBus
IBus 是 DBus 的子集,仅保留了读取 4 字节(word_t)的接口。
实验内容
下面将分步骤介绍本实验要完成的内容。
支持总线延时
在 mycpu_top.sv 的开头,有一个宏 FIXED_LATENCY 确定该模块使用类 SRAM 接口还是 AXI 接口:
/**
* TODO (Lab2) comment out the following line :)
*/
`define FIXED_LATENCY
module mycpu_top (
`ifdef FIXED_LATENCY
// ...
本次实验你需要将这一行 define 注释掉。之后
mycpu_top会使用 AXI 接口。- 仿真的顶层模块从
SRAMTop变成VTop。- 如果你上一次实验的地址翻译放在
SRAMTop,你可能需要将它们迁移到VTop。
- 如果你上一次实验的地址翻译放在
这里只修改了 mycpu_top 的接口,MyCore 依然使用 DBus/IBus。你不需要关心 AXI 接口是如何操作的。如果你感兴趣,可以自行阅读 util 文件夹下的 CBusToAXI.sv。
你需要修改流水线寄存器的阻塞逻辑。一条 lw 指令在 memory 阶段发出访存请求,在数据返回前,显然需要阻塞流水线。
一个简单的改动如下:
assign stallF = ~i_data_ok | ~d_data_ok;
assign stallD = ~i_data_ok | ~d_data_ok;
assign stallE = ~d_data_ok;
assign stallM = ~d_data_ok;
assign flushE = ~i_data_ok;
assign flushW = ~d_data_ok;
注意:这个处理的性能未必好,内存的写请求不一定需要进行 data_ok 的握手。
完成后,你应该能够通过 vivado/test1 的测试。
*实现仲裁器
我们已经提供了一个简单的仲裁器实现,在 source/util/CBusArbiter.sv 中。VTop 默认使用 CBusArbiter:
/**
* TODO (Lab2) replace mux with your own arbiter :)
*/
CBusArbiter mux(
.ireqs({icreq, dcreq}),
.iresps({icresp, dcresp}),
.*
);
CBusArbiter 有一个缺点,它需要花费一个时钟周期来确定谁有总线的访问权,无论是有多个请求还是只有一个请求。换句话说,CBusArbiter 会把所有的访存增加至少一个周期的延时。实际上这一个时钟周期可以被优化掉,只是这么做是要付出代价的。因为这种优化需要添加新的组合逻辑,有可能会增加关键路径的延时,导致 CPU 频率降低。
如果你想优化 CBusArbiter,请在 source/mycpu/MyArbiter.sv 中实现新的仲裁器,然后将 VTop 的 CBusArbiter mux 换成 MyArbiter mux。
另外请注意:CBusArbiter 默认的仲裁策略是 DBus 比 IBus 优先。如果你想调换优先级,请将上面 CBusArbiter mux 接口中的 icreq 和 dcreq 对换,以及将 icresp 和 dcresp 对换。
实现新的指令
“指令列表” 中有一张表,记录了 test1 到 test4 和所有性能测试会用到的指令。请据此确定 test2 需要添加的指令并实现。
test2 中需要额外实现的指令,主要有以下三类:
- 更多种类的分支跳转。
- 引入了以半字(16 位)和字节(8 位)为粒度的内存读写。
- 注意调整总线请求的
size部分,以及处理读写的数据。
- 注意调整总线请求的
- 移位的偏移量为寄存器数据。
接入 Verilator
下一轮实验会使用 Verilator 做模块级测试。本次实验先用 test1 和 test2,方便大家熟悉 Verilator 仿真的流程。
我们提供的测试框架里面,Vivado 仿真的顶层是 mycpu_top,而 Verilator 仿真的顶层用的通常是字母 V 开头的模块1(如 VTop、VCacheTop)。每一个顶层模块对应一个目标名称,也就是 make vsim 命令的 TARGET 参数。如果想以 source/mycpu/VTop.sv 这个文件作为顶层模块,其对应的 TARGET 就是 mycpu/VTop。
测试框架的代码放在 verilate/source 和 verilate/include 两个目录下。不同的顶层模块可能需要不同的测试代码,这些代码会分别放在 verilate/source 中对应子目录里面。如果 TARGET 是 mycpu/VTop,那么其专用的测试代码都放在 verilate/source/mycpu/VTop 下。我们提供了大部分 mycpu/VTop 的测试代码,目前这个目录下有:
defs.h:一些类型定义。mycpu.h:verilated 模型类的声明。mycpu.cpp:verilated 模型类的实现。vmain.cpp:仿真程序vmain的程序入口的代码。
所谓 verilated 模型是指把 SystemVerilog 描述的模块翻译成 C++ 代码后的一个 class。翻译后的 verilated 模型再和测试框架一起编译成可执行文件 vmain 后,运行 vmain 就会开始正式的仿真。
运行龙芯杯的 test1 和 test2 需要支持 trace 比对。你需要将 debug_* 信号暴露给 verilated 模型。以 writeback 阶段的 PC 为例,假设某个 CPU 结构如下面的代码所示:
module Writeback;
logic [31:0] pc;
endmodule
module MyCore;
Writeback wb;
endmodule
module VTop;
MyCore core;
endmodule
当 VTop 是顶层模块时,从 VTop 访问 PC 的跨模块引用应该写成 core.wb.pc。为了能在 Verilator 中访问到这个信号,首先你需要将 pc 声明为公开的:
module Writeback;
logic [31:0] pc /* verilator public_flat_rd */;
endmodule
/* verilator public_flat_rd */ 是一条 metacomment。其中 public 表示信号对外可访问,flat 表示信号名会被去层次化(flatten),rd 表示只读(read-only)。去层次化意思是 core.wb.pc 这个信号在翻译后的 C++ 代码中会以一个普通变量的方式呈现给 verilated 模型。C/C++ 的变量名里面不能有 “.”,因此 Verilator 会把 core.wb.pc 转换成 core__DOT__wb__DOT__pc。之后你需要修改 verilate/source/mycpu/VTop 文件夹中的 mycpu.cpp:
auto MyCPU::get_writeback_pc() const -> addr_t {
/**
* TODO (Lab2) retrieve PC from verilated model :)
*/
return VTop->core__DOT__wb__DOT__pc; // 访问 PC
}
这里 VTop 是指向顶层模块的作用域(scope)的指针,由 Verilator 自动生成。用 VTop 可以访问到先前模块内部公开的信号。当 C++ 代码调用上面这个函数时,就会返回当前 core.wb.pc 的值2。你还需要实现另外 3 个类似的函数。
之后在仓库根目录下运行:
make vsim TARGET=mycpu/VTop TEST=test1 -j
将会运行 test1。把 TEST=test1 换成 TEST=test2 就会运行 test2。test1 会输出以下内容:
./build/gcc/mycpu/VTop/vmain -m misc/nscscc/test1.coe -r misc/nscscc/test1.txt
(info) #1 completed.
(info) #2 completed.
(info) #3 completed.
(info) #4 completed.
(info) #5 completed.
(info) #6 completed.
(info) #7 completed.
(info) #8 completed.
(info) #9 completed.
(info) #10 completed.
(info) #11 completed.
(info) #12 completed.
(info) #13 completed.
(info) #14 completed.
(info) #15 completed.
(info) #16 completed.
(info) #17 completed.
(info) #18 completed.
(info) #19 completed.
(info) #20 completed.
(info) #21 completed.
(info) #22 completed.
(info) #23 completed.
(info) #24 completed.
(info) #25 completed.
(info) #26 completed.
(info) #27 completed.
(info) testbench finished in 337516 cycles (601.973 KHz).
随机延时
vmain 默认情况下并没有随机延时。可以使用 --p-disable/-p 参数开启随机延时。这个参数是一个概率值,表示内存每个周期无响应的概率。例如:
make vsim -j TARGET=mycpu/VTop TEST=test1 VSIM_ARGS='-p 0.99'
表示内存有 99% 的时间没有响应。如果设置为 -p 0,相当于关闭随机延时。
记录波形图
如果你不幸没有通过 vmain 的测试,看到了类似于下面的报错:
TextDiff: on line 18:
expect: "1 9fc03be0 10 00000001"
got: "1 9fc05100 10 00000001"
make: *** [verilate/Makefile.vsim.mk:123: vsim] Aborted (core dumped)
这是 trace 比对出错。你可能需要使用波形图来调试。为了加速仿真,make vsim 默认不会记录波形图。使用 --fst-trace/-f 参数开启波形图记录并且指定波形图文件保存的位置。例如:
make vsim TARGET=mycpu/VTop TEST=test1 -j VSIM_ARGS="-f build/trace.fst"
将会把波形图保存到 build 目录下的 trace.fst。仿真成功运行或者中途失败退出时,会保存 FST 波形图,并且能在终端输出看到一行信息:
FST trace: stop @558950
FST 格式的波形图文件需要用 GTKWave 打开:
gtkwave build/trace.fst
你需要自行摸索 GTKWave 的使用方式。我们提供了一份简短的使用说明:“使用 GTKWave”。
如果遇到你无法确定原因的错误,例如 assertion failed、segmentation fault 之类,有可能是测试框架的问题。请及时向助教反馈。如果遇到这些错误时,终端/命令行最后输出了 “(core dumped)”(上面 trace 比对出错的输出就有),说明这个错误可以使用 coredumpctl gdb 启动 GDB 查看。请进入 GDB 输入 backtrace 后回车,将调用栈打印出来,然后连同调用栈和错误信息一起反馈给助教。
总结
总结一下实验 2a 要做的事情:
- 修改取指和访存阶段的逻辑,支持多周期访存。
- 在 Vivado 仿真中通过
test1。
- 在 Vivado 仿真中通过
- *在
MyArbiter.sv中实现仲裁器。 - 根据 “指令列表” 添加新的指令。
- 在 Vivado 仿真中通过
test2。
- 在 Vivado 仿真中通过
- 修改
verilate/source/mycpu/VTop下的 C++ 代码。- 在 Verilator 仿真中通过
test1和test2。
- 在 Verilator 仿真中通过
- 通过
test1和test2上板测试。
以上是我们推荐的完成顺序。
实验提交
本实验和实验 2b 一起提交。
18307130024/
├── report/ (报告所在目录)
├── source/ (源文件所在目录)
└── verilate/ (仿真代码所在目录)
用 zip -r 18307130024.zip 18307130024/ 打包。用 unzip 18307130024.zip 检查,应在当前目录下有学号目录。
通过标准
- 通过以下四条命令的测试:
make vsim -j TARGET=mycpu/VTop TEST=test1make vsim -j TARGET=mycpu/VTop TEST=test1 VSIM_ARGS="-p 0.99"make vsim -j TARGET=mycpu/VTop TEST=test2make vsim -j TARGET=mycpu/VTop TEST=test2 VSIM_ARGS="-p 0.99"
- 上板通过
test1和test2。
实验报告要求
- 格式:PDF
- 内容:简要记录你所做的修改。写好姓名学号。附上测试通过时的照片或截图。
截止时间
2021 年 4 月 11 日 23:59:59
*思考题
-
张三在
source/util/CBusMultiplexer.sv中实现了自己的仲裁器,然而过不了仿真。请指出CBusMultiplexer存在的问题。 -
龙芯杯的测试框架中有一个叫做 CONFREG 的模块3,用来控制 FPGA 上的各种硬件资源,例如 LED 数码管、按钮。CONFREG 是一个 memory-mapped 设备。其中地址
0xbfaffff0是一个简化的 UART 打印接口,往这个地址写入 ASCII 码就可在仿真中输出文字。特别的,如果写入的值是0xff,就会立即停止仿真。李四写了一段汇编程序
hello.s,放在misc/hello目录下,它会打印 “Hello, world!”。但是李四买不起 CPU。请尝试将这段汇编代码编译成.coe文件,然后使用make vsim -j TARGET=mycpu/VTop VSIM_ARGS="-m [.coe 文件路径]"在你的 CPU 上运行这个程序。如果没有出错,
vmain最后会输出:./build/gcc/mycpu/VTop/vmain -m misc/hello/hello.coe Hello, world! (info) testbench finished in 652 cycles (515.101 KHz).至此,你
李四可以尝试在你的 CPU 上运行更加复杂的程序了。 -
王五最近学习了 AXI 总线协议。AXI 是一个双向握手协议。王五推荐你阅读 “ AMBA AXI Protocol Specification v1.0”,希望你能了解并总结 AXI 总线的工作方式。
VTop 用的是将在实验 3a 中介绍的 CBus(cache bus),是 AXI 总线的简化。Verilator 仿真的顶层模块和 Vivado 中不同的原因之一就是 CBus 模拟起来简单一些 :)
类型是 32 位的 uint32_t。
我们猜测这是 “configuration registers” 的缩写。
实验 2b:乘除法指令
增加乘除法指令和 HI、LO 寄存器,上板通过 test3 的测试。请自行翻阅指令列表和 MIPS 指令手册。
基本实现
两个 32 位数相乘的结果是 64 位,相除的结果包括 32 位商和 32 位余数。
MIPS 引入两个新的 32 位寄存器:HI 和 LO 来存储这 64 位结果。
这两个的寄存器写法和通用寄存器类似:
module hilo (
input logic clk,
output i32 hi, lo,
input i1 hi_write, lo_write,
input i32 hi_data, lo_data
);
i32 hi_new, lo_new;
always_comb begin
{hi_new, lo_new} = {hi, lo};
if (hi_write) begin
hi_new = hi_data;
end
if (lo_write) begin
lo_new = lo_data;
end
end
always_ff @(posedge clk) begin
{hi, lo} <= {hi_new, lo_new};
end
endmodule
以下是单周期乘除法器的一个参考写法:
module mult (
input i32 a, b,
input decoded_op_t op,
output i32 hi, lo
);
i64 ans;
always_comb begin
case (op)
MULTU: begin
ans = {32'b0, a} * {32'b0, b};
hi = ans[63:32]; lo = ans[31:0];
end
MULT: begin
ans = signed'({{32{a[31]}}, a}) * signed'({{32{b[31]}}, b});
hi = ans[63:32]; lo = ans[31:0];
end
DIVU: begin
ans = '0;
lo = {1'b0, a} / {1'b0, b};
hi = {1'b0, a} % {1'b0, b};
end
DIV: begin
ans = '0;
lo = signed'(a) / signed'(b);
hi = signed'(a) % signed'(b);
end
default: begin
{hi, lo, ans} = '0;
end
endcase
end
endmodule
*多周期乘除法器
参见:“Computer Architecture: A Quantitative Approach (6th Edition)”: Appendix J
32 位乘除法器的逻辑十分复杂,其单周期的实现延迟极高。
RefCPU 采用了单周期乘除法器。打开 test5 的 Vivado 工程 → 添加源文件 → “Run Implemented Design” → “Open Implemented Design”,查看延迟最高的一条路径,可得到下图中的信息:
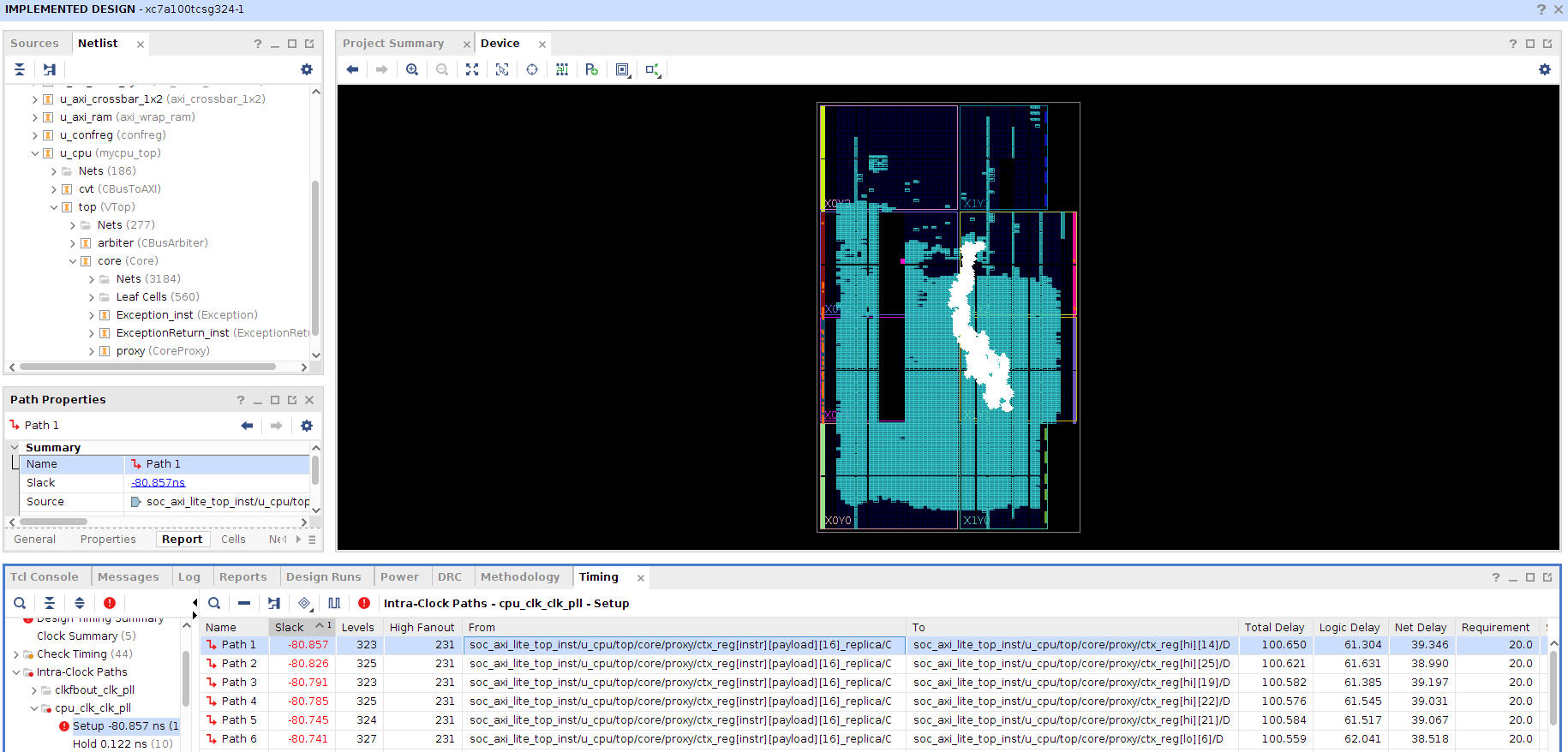
延迟最高的几条路径的终点都是 HI 和 LO 寄存器。这是除法操作的数据路径,逻辑级数高达 300,延迟高达 100ns,这就把 CPU 的频率限制在了 10MHz 以下。
实现乘除法器前,我们的五级流水线大概可达到 80MHz(关键路径的延迟约为 12ns)。如此大幅度的频率下滑,难以令人满意。我们已经划分了单周期 CPU 的数据通路(通过流水线),现在我们来划分一下乘法器和除法器,让单条乘除法指令在多个周期里执行。
让乘除法在多个周期里完成,会影响 IPC,但乘除法指令出现的频率很低,总体 IPC 的变化很小。而频率的下降会影响每条指令的执行效率。以下是一个简单的性能分析:
某程序有 500 条指令(无分支跳转),其中 10 条是除法指令,其余指令的数据通路延迟都很低。
- 使用单周期除法器的 CPU,时钟周期为 100ns,运行这个程序需要约 500 个周期,即 50,000ns。
- 使用多周期除法器的 CPU,时钟周期为 12ns,除法指令需要 50 个周期执行,运行这个程序需要约 1000 个周期,即 12,000ns。
乘法器
一种借用了竖式乘法的单周期乘法器(参考书 J.2 章节),实现如下:
module multiplier_singlecycle (
input i32 a, b,
output i64 c // c = a * b
);
i65 p;
always_comb begin
p[31:0] = a;
p[64:32] = '0;
for (int i = 0; i < 32; i++) begin
if (p[0]) begin // 每次循环扫a的一位
p[64:32] = p[63:32] + b; // 如果是1则加上b
// p[64:32] = p[64:32] + b; 更快
end
p = {1'b0, p[64:1]}; // 整体右移,需要检查的下一位被移至p[0]
end
end
assign c = p[63:0];
endmodule
这种方法的延迟约为 60ns。用注释里的那句语句,延迟约为 47ns(注释里的是 33 位加法,为什么比用 32 位加法更快?)。用乘法运算符实现单周期乘法时,Vivado 会调用实验板上的特殊运算资源 DSP,延迟约为 10ns。
这种方法有每一步的概念,可以很方便地拆分成多周期:每个时钟周期执行 1 次(或更多次)循环即可。另外,多周期乘法器需要一个计数器,记录乘法已进行的周期数。
module multiplier_multicycle_from_single (
input logic clk, resetn, valid,
input i32 a, b,
output logic done, // 握手信号,done 上升沿时的输出是有效的
output i64 c // c = a * b
);
enum i1 { INIT, DOING } state, state_nxt;
i35 count, count_nxt;
localparam i35 MULT_DELAY = {'0, 1'b1, 32'b0};
always_ff @(posedge clk) begin
if (~resetn) begin
{state, count} <= '0;
end else begin
{state, count} <= {state_nxt, count_nxt};
end
end
assign done = (state_nxt == INIT);
always_comb begin
{state_nxt, count_nxt} = {state, count}; // default
unique case(state)
INIT: begin
if (valid) begin
state_nxt = DOING;
count_nxt = MULT_DELAY;
end
end
DOING: begin
count_nxt = {1'b0, count_nxt[34:1]};
if (count_nxt == '0) begin
state_nxt = INIT;
end
end
endcase
end
i65 p, p_nxt;
always_comb begin
p_nxt = p;
unique case(state)
INIT: begin
p_nxt = {'0, a};
end
DOING: begin
if (p_nxt[0]) begin
p_nxt[64:32] = p_nxt[63:32] + b;
// p_nxt[64:32] = p_nxt[64:32] + b;
end
p_nxt = {1'b0, p_nxt[64:1]};
end
endcase
end
always_ff @(posedge clk) begin
if (~resetn) begin
p <= '0;
end else begin
p <= p_nxt;
end
end
assign c = p[63:0];
endmodule
本方法延迟约为 3.6ns(一个 32 位加法)。用注释里的那句语句,延迟约为 3ns。如果每周期做 4 次加法,周期数从 32 降至 8,延迟增加至 7.8ns。
本方法使用了 32 层加法器实现了乘法。如果是 位无符号数的乘法,本方法使用的加法器层数为 。Wallace tree 和 signed-digit tree 是加法器层数为 的算法,如果你对此感兴趣,可以查阅参考书 J.9 章节。
然而,我们发现,利用 DSP 资源,单周期乘法的性能已经不错了。

上图为使用 DSP 资源的单周期乘法器的关键路径。左侧的两个端口很多的元件 DSP48E1 即为 DSP ,右侧的若干 CARRY4 为加法逻辑。每片 DSP48E1 内置一个 25 位乘 18 位的乘法器,集成了乘加 的功能。
如果你想用 DSP 实现乘法器,请查阅 DSP48E1 的有关资料与手册。
Vivado 在解析乘法运算符时,默认采用 DSP 实现。我们可以将 32 位的乘法拆成若干个乘法,使每个乘法的位宽可以被 DSP 内置的乘法器所容纳,然后再将这些乘积进行移位相加。这样,在使用乘法运算符时,综合器就会简单地采用 DSP 中的乘法器。
下面的代码是一个简单的实现方案:将 32 位的乘法拆成四部分,两个乘数的前 16 位和后 16 位分别相乘,这样就是四个 16 位的乘法,可以用上 DSP 的乘法器。最后的加法里,两个低 16 位相乘的结果无需移位,高 16 位乘低 16 位的结果需要左移 16 位,两个高 16 位相乘的结果需要左移 32 位:
// c = (a[31:16] * b[31:16] << 32) + (a[15:0] * b[31:16] << 16) +
// (a[31:16] * b[15:0] << 32) + (a[15:0] * b[15:0])
module multiplier_multicycle_dsp (
input logic clk, resetn, valid,
input i32 a, b,
output logic done,
output i64 c // c = a * b
);
logic [3:0][31:0]p, p_nxt;
assign p_nxt[0] = a[15:0] * b[15:0];
assign p_nxt[1] = a[15:0] * b[31:16];
assign p_nxt[2] = a[31:16] * b[15:0];
assign p_nxt[3] = a[31:16] * b[31:16];
always_ff @(posedge clk) begin
if (~resetn) begin
p <= '0;
end else begin
p <= p_nxt;
end
end
logic [3:0][63:0] q;
assign q[0] = {p[0]};
assign q[1] = {p[1], 16'b0};
assign q[2] = {p[2], 16'b0};
assign q[3] = {p[3], 32'b0};
assign c = q[0] + q[1] + q[2] + q[3];
enum logic {INIT, DOING} state, state_nxt;
always_ff @(posedge clk) begin
if (~resetn) begin
state <= INIT;
end else begin
state <= state_nxt;
end
end
always_comb begin
state_nxt = state;
if (state == DOING) begin
state_nxt = INIT;
end else if (valid) begin
state_nxt = DOING;
end
end
assign done = state_nxt == INIT;
endmodule
本方法延迟约为 5.3ns,需要两个周期:第一个周期做四个并行的 16 位乘法(关键路径,延迟约为 5.3ns),第二个周期做剩余的加法(延迟约为 4.6ns)。这个方法用单周期实现,延迟约为 9.6ns。在接入流水线时,可能需要加一级输入寄存器。
本方法仅利用了 DSP 的乘法器和一层寄存器(经检测,乘法结果的那一级寄存器没有使用额外资源),没有利用乘加的功能,16 位的划分也不一定是最优方案,但性能已经令人满意。
除法器
一种借用了竖式除法的单周期除法器(参考书 J.2 章节),实现如下:
module divider_singlecycle (
input i32 a, b,
output i64 c // c = {a % b, a / b}
);
i64 p;
always_comb begin
p = {'0, a};
for (int i = 0; i < 32; i++) begin
p = {p[63:0], 1'b0};
if (p[63:32] >= b) begin
p[63:32] -= b;
p[0] = 1'b1;
end
end
end
assign c = p;
endmodule
本方法延迟约为 93ns(直接用除法运算符的单周期除法器延迟约为 80ns)。
类似地,可以将它拆分成多周期:
module divider_multicycle_from_single (
input logic clk, resetn, valid,
input i32 a, b,
output logic done,
output i64 c // c = {a % b, a / b}
);
enum i1 { INIT, DOING } state, state_nxt;
i35 count, count_nxt;
localparam i35 DIV_DELAY = {'0, 1'b1, 32'b0};
always_ff @(posedge clk) begin
if (~resetn) begin
{state, count} <= '0;
end else begin
{state, count} <= {state_nxt, count_nxt};
end
end
assign done = (state_nxt == INIT);
always_comb begin
{state_nxt, count_nxt} = {state, count}; // default
unique case(state)
INIT: begin
if (valid) begin
state_nxt = DOING;
count_nxt = DIV_DELAY;
end
end
DOING: begin
count_nxt = {1'b0, count_nxt[34:1]};
if (count_nxt == '0) begin
state_nxt = INIT;
end
end
endcase
end
i64 p, p_nxt;
always_comb begin
p_nxt = p;
unique case(state)
INIT: begin
p_nxt = {'0, a};
end
DOING: begin
p_nxt = {p_nxt[63:0], 1'b0};
if (p_nxt[63:32] >= b) begin
p_nxt[63:32] -= b;
p_nxt[0] = 1'b1;
end
end
endcase
end
always_ff @(posedge clk) begin
if (~resetn) begin
p <= '0;
end else begin
p <= p_nxt;
end
end
assign c = p;
endmodule
本方法延迟约为 3.6ns ,周期数为 32。
有符号数的处理
上面提到的所有实现,都是针对无符号数的,没有考虑有符号数的符号位。
对于有符号数的乘除法,一种简单的处理方法是将有符号数取绝对值,再进行乘除法,最后再恢复符号位,这样就可以复用无符号数的乘除法器了。
乘法的转换比较简单,这里仅举一个例子:当 时,。
除法的处理复杂一些:
流水线控制逻辑
如果你采用了多周期的乘除法器,那么你需要在流水线的控制逻辑里,添加新的阻塞条件。
一个简单的实现是,遇到乘除法指令时,阻塞流水线至其计算完毕。
MIPS 将乘除法指令的结果写入 HI 和 LO 寄存器,而非通用寄存器,并通过 MFLO 和 MFHI 来读取结果到通用寄存器内。编译器有时会在乘除法指令后插入几条不相关的普通指令,再用 MFLO 和 MFHI 来读取结果。这样,在计算乘除法结果的这几个周期里,流水线可以继续执行;遇到接下来的第一条 MFLO 或 MFHI 时,如果没计算完毕,再阻塞;如果已计算完毕,就直接读取结果,相当于乘除法指令没有造成任何阻塞。这是一种潜在的优化,优化的效果取决于编译器。
实验提交
本实验和实验 2a 一起提交。
通过标准
- 上板通过
test3的测试。
截止时间
2021 年 4 月 11 日 23:59:59
*思考题
-
李四发现 Verilator 仿真的 CONFREG 模块提供了简单的串口交互接口:地址
0xbfaf1000用于在串口上读写字符,地址0xbfaf1014用于检查是否有未读入的字符。于是李四在misc/echo下编写了一个汇编程序echo.s,它会把你在终端上输入的字符显示出来。请先尝试将echo.s编译成.coe文件。打开一个终端,在仓库根目录下运行
make vpty。这个命令会使用socat在build目录下创建一个虚拟控制台(pty)。然后再打开一个终端,运行:make vsim -j TARGET=mycpu/VTop VSIM_ARGS="-m [.coe 文件路径]"此时
vmain会自动接入到之前make vpty创建的虚拟控制台的一端,并且会在仿真的终端打印一行 “CONFREG: connected to pty "build/vpty".”。最后再打开一个终端,运行串口软件。以 GNUscreen为例:screen build/pty然后尝试输入字符,你会看到这些字符在串口软件的终端里能显示出来。此时如果杀死
vmain进程,再到串口软件上输入时,就看不到新输入的字符了。此时,你
李四可以尝试编写在终端上交互的程序了。李四的echo.s还不支持 backspace 键,你可以思考一下如何实现 backspace。提示:你可以使用
showkey查看键盘上每个按键对应的 ASCII 码。 -
李四学会了 C 语言,于是他在
misc/greet目录下写了一份 C 程序greet.c。这个程序会读入一行文字,比如 “Gromah”,当你按下回车后,程序会在下一行中显示 “Hello, Gromah!”。请尝试将这个程序编译到.coe文件,并在你的 CPU 上运行。
实验 3a:高速缓存
高速缓存(cache)对于 CPU 性能十分重要。如果没有缓存,流水线做的所有优化都是徒劳的。本次实验需要实现第一级缓存中的数据缓存(L1d)。由于我们的 CPU 的取指和访存的需求基本一致,因此 L1d 可以直接拿来当 L1i 使用。

上图是目前消费级多核处理器中非常常见的缓存架构。lscpu -C 命令可以列出你的 CPU 上各级缓存的信息:
$ lscpu -C
NAME ONE-SIZE ALL-SIZE WAYS TYPE LEVEL SETS PHY-LINE COHERENCY-SIZE
L1d 32K 128K 8 Data 1 64 1 64
L1i 32K 128K 8 Instruction 1 64 1 64
L2 256K 1M 4 Unified 2 1024 1 64
L3 8M 8M 16 Unified 3 8192 1 64
缓存是利用程序局部性原理的经典例子。32KiB 的 L1d 和 L1i 足以在龙芯杯的性能测试得到 99% 的缓存命中率。
L1i & L1d
一级缓存分为指令缓存和数据缓存,分别服务于取指和访存阶段。原则上 L1i 是只读的,并且不会有程序在运行过程中写入新的指令1,因此我们不需要考虑两个缓存之间同步的问题。
实现 L1d
本次实验要求 L1d 是写分配(write-allocate)和写回(write-back)的缓存。你需要在 DCache.sv 中编写你的实现。
接下来我们将介绍 L1d 的基本结构。
Cache Line
Cache line 包含一段连续的内存的副本,一般情况下它的大小是一个 2 的幂次,并且起始地址和大小对齐。当缓存从内存中读取出一条 cache line 时,缓存可以利用内存的突发传输特性,从而降低每个字节的平均读取延时。我们使用的 32 位 AXI 总线一般可以支持单次最高 16×4 = 64 字节的突发传输,因此我们也建议你在性能测试中使用大小为 64 字节的 cache line。从 L1i 的角度来看,相当于每条 cache line 放了 16 条指令。
如果选择大小为 64 字节的 cache line,那么内部的偏移量(offset)需要 6 位。对于 L1i,由于指令都是和 4 字节对齐的,因此只需要 4 位。


Cache Set
前面说的 cache line 是缓存和内存交互的基本单元。缓存将内存视为一大堆 cache line 的集合。之后我们需要考虑如何在缓存中索引 cache line。
最常见的做法是把缓存分为若干个桶,每个桶内可以存放一定数量的 cache line,有点类似于哈希表。这些桶在缓存的术语中叫做 cache set。一般地址中除去 offset 后最低的几位会被拿来当作 cache set 的索引(index):

每个 cache set 内能同时存储的 cache line 条数称为关联度(associativity)。显然关联度至少为 1。常见的关联度有 2、4、8(也就是所谓的 2 路、4 路、8 路缓存)。由于很多的 cache line 会被映射到同一个 cache set 内,我们必须用地址中剩下的位对它们进行区分。这些位通常也称作标签(tag):

当我们索引 cache line 时,通常会在 cache set 内并行地比较 tag。因此,关联度太大会导致缓存中比较器消耗的硬件资源过多,反而会降低缓存性能。
为什么使用低位作为索引值?
看一个现实生活中的例子:

(杨浦区某快餐店的外卖暂存区。右下角应该是数字 “9”) 上图中货架上每个数字下面写着 “订单尾号”。
该快餐店的订单号是按顺序生成的。因此用低位作为索引有助于充分利用货架上的每个隔间。也正因为顺序生成的订单号,所以在一段时间内产生的外卖的订单号的高位都是一样的。如果用高位,就会导致大量的外卖放在同一层内。
总结一下:
- offset 用于 cache line 内的寻址。
- index 用于索引到 cache set。
- tag 用于区分同一个 cache set 内不同的 cache line。
替换策略
缓存的大小通常远小于内存的大小,所以一个程序运行过程中所需要用到的所内存大概率不能都放入缓存中。缓存的主要目标是把程序近期会用到的内存全部装入缓存,这些内存通常也称为工作集(working set)。因此,缓存经常需要把不常用的 cache line 从缓存中清出去,为接下来需要访问的 cache line 腾出空间。
举个例子,对于一个 4 路缓存,某个 cache set 已经有 4 条 cache line 了,然后 CPU 访问的下一个地址对应的 cache line 不在缓存中,但也是映射到这个 cache set 的。此时缓存必须把这个 cache set 内已有的某条 cache line 替换掉,从而能够存放新的 cache line。那么此时应该将哪条 cache line 替换出去呢?
想必各位在 ICS 课上已经了解过各种替换策略了,因此这里不会再一一列举。简单来说,如果我们知道程序的访存顺序,那么我们只需要将下次访问时间最晚的 cache line 替换掉即可。这个贪心算法可以证明是最优的。但显然我们无法准确得知程序的行为。LRU 算法和它的各种变种是缓存中常用的替换算法。LRU 在大多数情况下的效果都比较接近最优贪心算法的效果2。最原始的 LRU 算法需要维护 cache set 内每条 cache line 的顺序,在硬件上实现可能比较消耗资源,因此出现了一些 LRU 的变种算法。此外,随机替换策略在缓存关联度足够大的时候也有不错的表现。并且随机替换不需要在访存缓存时更新替换算法的状态,也不需要每个 cache set 都存放额外信息。相比于 LRU 系列,随机替换可以节约大量的硬件资源。
本次实验中你可以实现任意的替换策略。
状态机
缓存的状态机可以有两种理解:
- 缓存本身是一个大的状态机,下面管着很多的 cache line。
- 缓存先索引到一个 cache line,然后每条 cache line 都有一个独立的状态机。
在我们的实验中,上面两种理解没有太大区别。对于有多个端口且支持并发访问的缓存而言(例如 L2),可能第二种理解更加贴切。
Cache line 有三种基本的状态3:
- Invalid:无效状态。这条 cache line 还没有被装入任何有效的数据。
- Valid:有效状态。这条 cache line 中有数据,且和内存中的内容相同。
- Dirty:已被写入状态。这条 cache line 中有数据,但是先前被 CPU 写入了新的数据,导致 cache line 中的内容和内存中对应位置处的内容不一致。
这三种状态一般称为稳定状态(stable states)。当然,从 invalid 变到 valid 需要进行一次突发传输,这需要经过多个周期才能完成,因此需要设立额外的过渡状态(transient states)。
你需要设计一个维护每条 cache line 状态的状态机。具体而言,你的状态机至少需要能处理下面几种事件:
- 缓存命中(cache hit):CPU 发出请求,并且在缓存内找到了对应的处于 valid/dirty 状态的 cache line。
- 缓存不命中(cache miss):CPU 发出请求,但是没有找到对应的处于 valid/dirty 状态的 cache line。
- 读取 cache line:突发传输中返回了新的数据。
- 写回 cache line:当 dirty 的 cache line 被替换时,需要使用突发传输将整个 cache line 写回到内存中。
存储和索引
对于每条 cache line,我们需要存储:
- cache line 的数据。
- cache line 的 tag、状态信息。通常称为元数据(metadata)。
对于每个 cache set,你需要存储一个 cache line 的数组。
假设 index 和 offset 都是 6 位,关联度为 4,下面是一个简略的实现:
typedef i20 tag_t;
typedef i6 index_t;
typedef i6 offset_t;
typedef i2 position_t; // cache set 内部的下标
typedef struct packed {
tag_t tag;
logic valid; // cache line 是否有效?
logic dirty; // cache line 是否被写入了?
} meta_t;
typedef meta_t [3:0] meta_set_t;
typedef word_t [15:0] cache_line_t;
typedef cache_line_t [3:0] cache_set_t;
// 存储单元(寄存器)
meta_set_t [63:0] meta;
cache_set_t [63:0] data;
// 解析地址
tag_t tag;
index_t index;
offset_t offset;
assign {tag, index, offset} = dreq.addr;
// 访问元数据
meta_set_t foo;
assign foo = meta[index];
// 搜索 cache line
position_t position;
always_comb begin
position = 2'b00; // 防止出现锁存器
if (foo[0].tag == tag)
position = 2'b00;
else if (foo[1].tag == tag)
position = 2'b01;
else if (foo[2].tag == tag)
position = 2'b10;
else if (foo[3].tag == tag)
position = 2'b11;
end
// 访问 cache line
cache_line_t bar;
assign bar = data[index][position];
assign dreq.data = bar[offset[5:2]]; // 4 字节对齐
针对缓存的实现,我们有如下的建议:
-
实现参数化。主要是为了方便修改缓存的大小。你可以在
DCache模块的声明处添加自定义的参数,例如:module DCache #( parameter int OFFSET_BITS = 4, parameter int INDEX_BITS = 2, localparam int TAG_BITS = 32 - OFFSET_BITS - INDEX_BITS ) ( // 接口列表 );上面的
parameter是外部可以改动的参数,例如DCache #(.OFFSET_BITS(6)) dcache_inst(.*);而
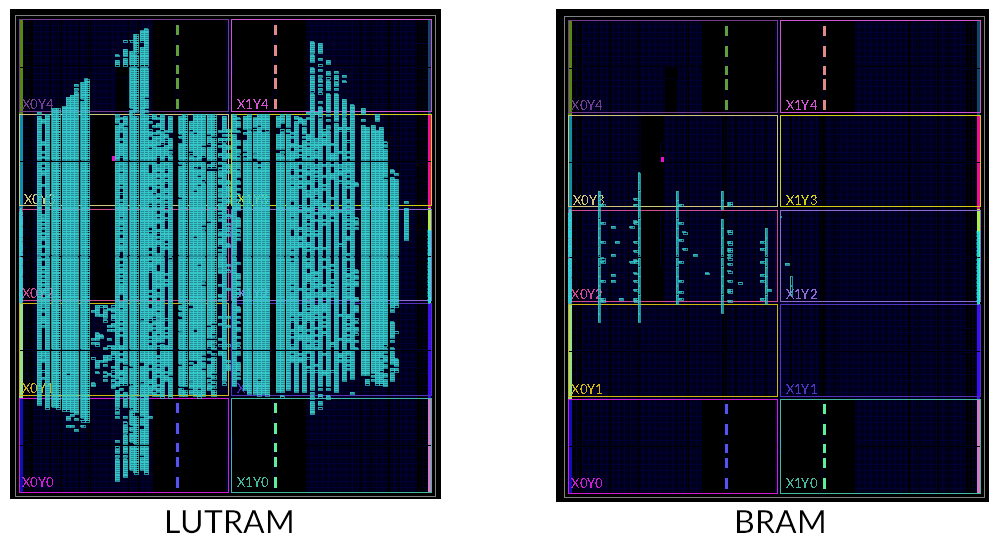
localparam仅限模块内部使用,类似于常量值(比如 C++ 中的constexpr)。 -
强烈建议初次调试时不要使用太大的缓存。我们推荐最开始调试的时候使用 4 位的 offset 和 2 位的 index,并且关联度不要超过 4。这相当于每条 cache line 存储 4 条指令,缓存中只有 4 个 cache set。过长的 cache line 会让突发传输的过程太长,而过多的 cache set 和过大的关联度会增加在缓存中寻找问题的难度。一般 4 个足以测试出绝大部分的问题。
-
*使用 LUTRAM 存储 cache line。我们在
source/ram目录下提供了LUTRAM.sv和LUTRAMTest.sv,它们分别是 LUTRAM IP 核的封装和测试4。使用 LUTRAM 可以大幅减少你的缓存消耗的硬件资源。你可以在 Vivado 中观察LUTRAMTest.sv的仿真波形图,或者是阅读LUTRAM.sv内的行为级模型的 SystemVerilog 代码,来了解 LUTRAM 的行为。我们也提供了source/refcpu/StupidBuffer.sv作为使用 LUTRAM 的示例。
接口
缓存是放在 CPU 流水线和内存之间的,因此:
- 缓存对 CPU 提供一个 DBus 的接口,并且保证缓存是透明(transparent)的。即从 CPU 来看,无论有没有缓存,访存的接口应该都是一致。
- 缓存在内存这边使用 CBus 接口,方便利用突发传输。
缓存总线(CBus)
CBus 是对 AXI 总线突发传输接口的简化。
typedef struct packed {
logic valid; // 是否发出请求
logic is_write; // 是否是写请求
msize_t size; // 单次传输的字节数
addr_t addr; // 突发传输起始地址
strobe_t strobe; // 单次传输中的写使能信号
word_t data; // 单次传输中的写数据
mlen_t len; // 总传输次数
} cbus_req_t;
typedef struct packed {
logic ready; // 上一次传输是否完成
logic last; // 最后一次传输是否完成
word_t data; // 单次传输读取的数据
} cbus_resp_t;
CBus 的突发传输实际上就是 AXI 总线中的 WRAP 类型的突发传输。在 AXI 总线中,每次突发传输称为一次事务(transaction)。事务内可以有多次数据传输的总线握手(burst)。
事务有几个基本属性:
- 是否有效:
valid为 1 表明事务有效。 - 写事务/读事务:由
is_write决定。 - 单次读写大小:由
size决定。可以为MSIZE1(单字节)、MSIZE2(双字节)或者MSIZE4(4 字节)。 - 起始地址:由
addr给出。 - 总传输/握手次数:由
len给出。可以为MLEN1、MLEN2、MLEN4、MLEN8和MLEN16中的一种。
以上 5 项作为事务的属性,在事务进行中是不能变更的。
和 DBus 类似,CBus 的握手也是在时钟周期上升沿时进行的。其中 ready 为 1 表示操作完成,而 last 为 1 表明这是这个事务中最后一次握手。当 last 为 1 的握手完成之后,如果接下来没有其它事务需要进行了,那么 valid 应该设为 0。当然你是知道总共会做多少次传输的,所以 last 可以换成你自己的计数器。
前面还剩下 strobe 和 data 两个信号没有说明。首先,这两个信号和 DBus 中类似,也相当于有 4 个 byte lane,这里就不再赘述。其次,这两个信号是单次传输时用到的信号,因此在事务进行过程中可以变动。每当 ready 信号握手成功后,strobe 和 data 就应该换成下一次传输的数据。你可能注意到 addr 在这个过程中是不变的,这是因为每次传输时的具体位置 real_addr 是从 addr 开始累加的,即每次传输成功后,real_addr 加上 size。此外,由于我们用的是 WRAP 类型的传输,所以事务传输的范围是和 size×len 个字节对齐的。例如,当 size 是 MSIZE4,而 len 是 MLEN4 时,会和 4×4 = 16 字节对齐。如果 addr 是 0x1f8,那么 real_addr 将依次为 0x1f8、0x1fc、0x1f0 和 0x1f4。
特别的,AXI 事务传输允许 addr 不用和 size 对齐。此时第一次传输相当于非对齐传输,而之后传输依然会按照对齐的地址进行传输。例如,当 size 是 MSIZE4,而 addr 是 0x1f5 时,real_addr 依次为 0x1f5、0x1f8、0x1fc...
下图是一个从地址 0xbfc01fc1 开始连续传输 15 个字节 0x11~0xff 的示例:

上图中,四次握手的实际地址分别为 0xbfc01fc1、0xbfc01fc4、0xbfc01fc8 和 0xbfc01fcc。
在 verilate/include/axi.h 有 AXI WRAP 突发传输的 C++ 描述。
参考实现
source/refcpu/StupidBuffer.sv 是一个参考实现。StupidBuffer 中展示了如何进行突发传输,并且同时将突发传输中的数据保存到 LUTRAM。
模块级测试
本次实验使用 Verilator 对缓存做专门的测试。
与之前不同,这次用了一个新的名为 VCacheTop 的顶层模块,它只接入了缓存,没有带上流水线。同时,测试你的缓存的 C++ 代码也放到了 verilate/source/mycpu/VCacheTop 下面。
用下面的命令运行模块级测试:
make vsim -j TARGET=mycpu/VCacheTop VSIM_OPT=1
加入 VSIM_OPT=1 的原因是后面的单元测试非常大,不进行编译器优化会非常慢。
如果测试全部通过,最后应该能看到:
(info) 27 tests passed.
单元测试
这中间最重要的文件是 verilate/source/refcpu/VCacheTop/tests.inl,这里面包含了本次实验所有的单元测试。mycpu/VCacheTop 文件夹下的 tests.cpp 里面直接 include 了 tests.inl,也就是说我们将用测试 StupidBuffer 的单元测试来测试你的缓存。每个单元测试形如:
// this test is explicitly marked with "SKIP".
WITH SKIP {
bool one = 1, three = 3;
ASSERT(one + one == three); // trust me, it must fail
// but you should not fail here since it's skipped.
} AS("akarin~");
可以看到,单元测试的代码用 WITH...AS("...") 包起来,AS 后面的字符串是这个单元测试的名字。测试内部使用 ASSERT 检查测试状态。如果状态与预期不符,ASSERT 会直接中断这个测试并报错。此外,WITH 后面可以带上一些插件(plugin),例如上面的 SKIP,表明这个测试会直接跳过。
具体的测试内容需要你自己阅读 tests.inl。
对照测试
有些测试使用了 CMP_TO 插件,例如:
WITH CMP_TO(ref) {
for (size_t i = 0; i < CMP_SCAN_SIZE / 4; i++) {
dbus->storew(4 * i, randi<uint32_t>());
dbus->loadw(4 * i);
}
} AS("cmp: word");
此时需要你自己编写你的缓存的对照模型(reference model)。所谓对照模型,就是用 C++ 描述你的缓存的各种行为。其中会包含诸如替换策略、内部状态等各种信息。测试框架会在运行 verilated 模型的同时也运行你的对照模型,并且在每次访存操作(load 或者 store)完成后,将对照模型的内部状态和 verilated 模型进行比较,如果不一致就报错(由 CacheRefModel::compare_internal 实现)。并且,在单个测试结束时,也会将对照模型的内存和 verilated 模型中的内存进行比较(由 CacheRefModel::compare_memory 实现)。
你需要将 cache_ref.h 和 cache_ref.cpp 中的所有 TODO 全部实现,然后才能通过这些测试。
请注意:对照模型的仿真不是以时钟周期为单位的,而是以访存操作为单位的。也就是说:
auto CacheRefModel::load(addr_t addr, AXISize size) -> word_t {
// ...
}
void CacheRefModel::store(addr_t addr, AXISize size, word_t strobe, word_t data) {
// ...
}
分别表示向缓存读取和写入的操作,而这两个函数的目标是计算操作完成后,理论上缓存的内部状态是怎么样的。测试框架在向 verilated 模型发送请求并等待 verilated 模型完成后,将先调用对应的函数,然后调用 compare_internal 来检查内部状态。
编写对照时需要从 C++ 访问 SystemVerilog 模块中的变量。请注意 Verilator 会把所有变量默认当作 bit 数组处理(类似于 C++ 中的 std::bitset),所以位数较多的多维数组和结构体在 C++ 的 verilated model 中都是整型数组。目录 misc/verilator-example/access 下的 Bits.sv 和 Bits.cpp 包含了一些 C++ 访问 SystemVerilog 变量的例子。你可以参考这个例子来实现 check_internal 和 check_memory。
调试工具
在单元测试的 WITH 后面加上 TRACE,就会在运行测试的中途记录 FST 波形图。默认会把波形图放在 build 文件夹下面。例如:
WITH TRACE {
// ...
} AS("example test 1");
将会把波形图记录到 build/example-test-1.fst 这个文件中。
类似的,在 WITH 后面加上 DEBUG,将会在终端打印所有访存操作。对比较小的测试可能有用。
参考实现
verilate/source/refcpu/VCacheTop 下面有 StupidBuffer 的配套代码。这可能是唯一比较靠谱的参考代码了 :)
*性能监测
tests.inl 最后的四个测试分别会在你的缓存上运行 std::sort、std::stable_sort、堆排序和二叉树插入和搜索算法。它们都使用了一个名为 STAT 的插件。此时你需要实现 mycache.h 和 mycache.cpp 下面的所有 TODO,主要是 reset_statistics、update_statistics 和 print_statistics 这三个函数。它们分别表示重置统计信息、更新统计信息和打印统计信息。
你可以在这里统计你的缓存的命中率、突发传输所用周期数等信息。测试框架在每个单元测试开始的时候会调用 reset_statistics;然后在仿真过程中,每个周期都会调用一次 update_statistics;测试结束时,会调用 print_statistics 来打印这个测试的统计信息。StupidBuffer 的配套代码中,实现了 StupidBuffer 各个状态所用周期数的计数器,在测试中会输入如下的内容:
"std::sort": [IDLE]=8441412, [FETCH]=143504004, [READY]=8441412, [FLUSH]=19608616
[OK] std::sort (11921ms)
"std::stable_sort": [IDLE]=5331138, [FETCH]=90629346, [READY]=5331138, [FLUSH]=2550000
[OK] std::stable_sort (7313ms)
"heap sort": [IDLE]=5569012, [FETCH]=94673204, [READY]=5569012, [FLUSH]=2550000
[OK] heap sort (7054ms)
"binary search tree": [IDLE]=7868866, [FETCH]=133770722, [READY]=7868866, [FLUSH]=34292706
[OK] binary search tree (10670ms)
*自定义测试
如果有需要,你可参照已有的单元测试代码,在 mycpu/VCacheTop/tests.cpp 中编写你自己的单元测试。
如果你尝试对缓存进行优化,你也可以用单元测试来检测优化的效果。
*并行测试
为了加快测试速度,你可以使用下面的命令:
make vsim -j TARGET=mycpu/VCacheTop VSIM_OPT=1 VSIM_ARGS="-j4"
其中 -j4 表示使用 4 个进程一起跑单元测试5。
实验提交
本次实验和实验 3b 一起提交。
18307130024/
├── report/ (报告所在目录)
├── source/ (源文件所在目录)
└── verilate/ (仿真代码所在目录)
用 zip -r 18307130024.zip 18307130024/ 打包。用 unzip 18307130024.zip 检查,应在当前目录下有学号目录。
通过标准
- 通过模块级测试。
make vsim -j TARGET=mycpu/VCacheTop VSIM_OPT=1make vsim -j TARGET=mycpu/VCacheTop VSIM_OPT=1 VSIM_ARGS="-p 0.5"
实验报告要求
- 格式:PDF
- 内容:
- 简要描述你设计的缓存。
- 如果你尝试做了优化,请举例说明优化的效果。
- 写好姓名学号。附上测试通过时的照片或截图。
截止时间
2021 年 5 月 10 日 12:00
*思考题
- 在关联度为 的缓存中实现 LRU 算法时,每个 cache set 最少需要为 LRU 算法记录多少位的额外信息?
- 缓存在重置(reset)的时候,除元信息外,是否需要将每条 cache line 内的数据也重置?如果不重置会有什么影响?如果重置又会有什么影响?
- 模块级测试的最后四个测试使用了
MemoryCell,它表示 verilated 模型中指定地址处的一个小内存单元。所有读写类型为MemoryCell的变量的操作都会被重定向到 verilated 模型的仿真上。这样一来就能非常方便地在你的缓存上跑各种算法了。- 请尝试使用
MemoryCell编写一个新的单元测试。你可以在这个测试内跑任意算法。 MemoryCell是否真的把所有的访存操作都重定向了?如果是,请说明理由。如果不是,请指出有哪些访存没有被重定向。- 你有不同于
MemoryCell的解决方案吗?
- 请尝试使用
- 张三发现,在先前
lscpu -C的例子中,L1i/L1d 的 set 数量(SETS)只有 64,远小于 L2 的 set 数量,但是 L1i/L1d 的关联度(WAYS)是 8,反而比 L2 大。为什么它不选择把 L1i/L1d 的关联度降到 4,并且把 set 数量提高到 128 呢? - 文档中
lscpu -C的输出来自 Intel 的 Coffee Lake 微架构的 i5 8300H。该 CPU 的 L3 是一个 (strictly) inclusive cache6。结合 WikiChip 上的信息,请尝试解释为什么 L3 的关联度是 16。
但实际上像 JVM、Javascript V8 这种利用 JIT 技术的软件可能会有这种需求。MIPS 架构中提供了 CACHE 指令来解决这个问题。
如果是在链表上做更新,Sleator & Tarjan 证明了 LRU 算法和最优算法的操作数是同一个级别的:“Amortized Efficiency of List Update and Paging Rules”。
在多核的缓存系统中,由于需要维护缓存一致性,可能会有更多的状态。例如在 MOSEI 缓存一致性协议中,每条 cache line 的状态可能是 Modified、Owner、Shared、Exclusive 或者 Invalid 中的一种。
你可能发现 source/ram 目录下还有一个 BRAM.sv。我们在本次实验中不推荐你用 BRAM,因为 BRAM 的读写有至少一个周期的延时。
由于并行测试用到了 fork,所以目前仅支持在 Linux 环境中使用。
参见 Wikipedia 以及网上的资料。
实验 3b:接入流水线
完成缓存的模块测试后,你的 L1i/L1d 应该能够无缝接入流水线了 :)
实验步骤
实验 3a 中,我们要求大家在 DCache.sv 里面实现 L1d。接下来将介绍接入流水线的步骤。
L1i
我们提供的代码里面,L1i 是写在 ICache.sv 里面,并且直接使用 L1d:
// simply use DCache as ICache
DCache proxy(
.dreq(`IREQ_TO_DREQ(ireq)),
.dresp(iresp),
.dcreq(icreq),
.dcresp(icresp),
.*
);
得益于 IBus 是 DBus 的子集,我们不需要做总线的转换。
如果你精力旺盛,可以专门实现一个 L1i。
替换转接器
在 VTop.sv 中,你需要将模块实例 icvt 和 dcvt 的模块名 IBusToCBus、DBusToCBus 分别换成 ICache、DCache。我们特意把缓存的模块接口做的和 DBusToCBus 这些总线转接器一样,方便我们继续使用 SystemVerilog 的 .* 语法。
ibus_req_t ireq;
ibus_resp_t iresp;
dbus_req_t dreq;
dbus_resp_t dresp;
cbus_req_t icreq, dcreq;
cbus_resp_t icresp, dcresp;
MyCore core(.*);
/*IBusToCBus*/ ICache icvt(.*);
/*DBusToCBus*/ DCache dcvt(.*);
处理地址映射
然而,单纯将总线接口替换掉还不够,因为并不是所有的内存区域都是可以被缓存的。一类是访问外设,显然我们不希望写入 UART 设备的字符要等到对应的 cache line 被替换掉时才发出。此外,这些外设可能也不支持突发传输。
那我们怎么知道可不可以缓存呢?MIPS 规范将内存空间划分为了若干段:
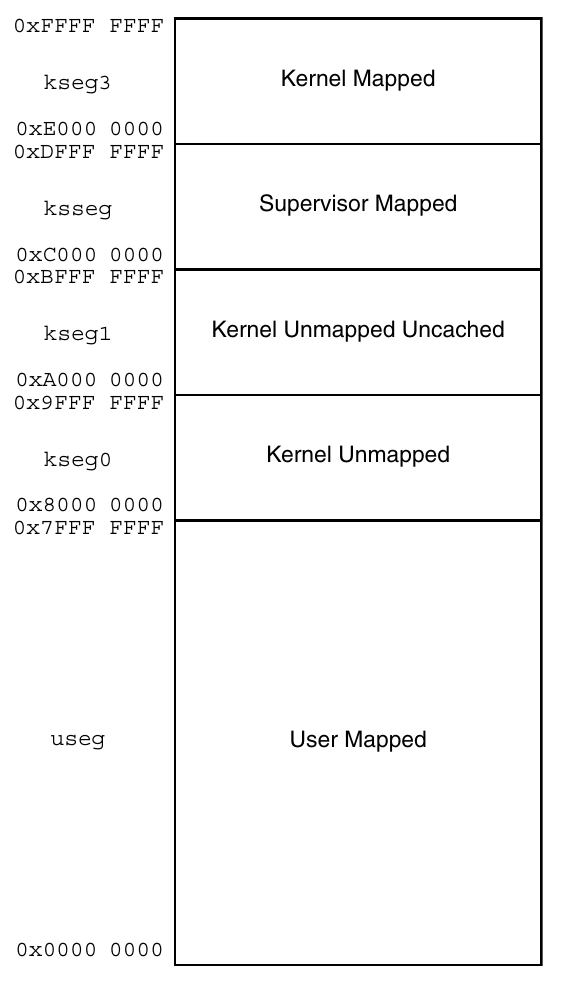
上图左侧是每个段的名称(例如 useg、kseg0)以及对应的地址范围。右侧是段的属性,这些属性的意义如下:
- User/Supervisor/Kernel:访问这一段的最低权限。我们暂时可以不用管。
- Mapped/Unmapped:这一段内的地址是否需要经过 TLB 翻译。我们暂时不用实现 TLB,因此所有 mapped 的段也不用管。
- Uncached:这一段内的所有访存要求不能经过缓存。
先前我们做了 kseg0 和 kseg1 的地址翻译。这里可以看到,kseg1 内的访存是要求不能过缓存的,而 kseg0 是允许的。CPU 的重置 PC(0xbfc00000)是在 kseg1 的,这是为了避免缓存在机器起动的时候需要初始化。同时龙芯杯的 CONFREG 模块也是映射到 kseg1 内的(0xbfaf0000~0xbfafffff)。kseg0 和 kseg1 都映射到同样的物理地址区域上。
总而言之,你需要能够允许有不经过缓存的访存路径。你需要自己思考该如何在 VTop 中处理这些事情。一种思路是:
- 在缓存之前做地址翻译,地址翻译输出一个
uncached信号表明当前访存的地址是否能经过缓存。 - 增加更多的访存接口,一些接到缓存,另一些直接使用
IBusToCBus、DBusToCBus转为 CBus 接口。 - 最后把所有输出的 CBus 接口(最多应该有 4 个)用仲裁器合并为一个 CBus 接口输出。我们提供的
CBusArbiter支持参数化(通过NUM_INPUTS参数),可以支持多于两个输入的仲裁。
另一种思路是直接在缓存内部决定是否经过缓存。
测试
完成上面的事情后,用 test1~test3 来测试你的 CPU。你应该能观察到接入缓存后这些测试花费的时间和周期数都少了很多。
*我们推荐你用性能测试算算分。有缓存后应该能够得到比较好的分数了 :)
*优化缓存
接下来介绍几个简单的优化技巧。
*Skid Buffer
流水线和缓存的交互容易产生非常长的关键路径,例如:

上图展示了一种可能的关键路径:
- 访存阶段发出请求。在发请求前需要做一点组合逻辑判断是否需要发出请求(
valid)。 - 缓存搜索请求的地址是否在缓存中,并由此决定
addr_ok。 - 流水线根据
addr_ok决定是否需要阻塞,产生stall信号。
stall 信号需要跨过多个流水线阶段,所以往往走线延时比较长。这里的问题主要出在握手信号(valid 和 addr_ok)之间有组合逻辑。Skid buffer 可以缓解这个问题。

Skid buffer 是插入在总线之间的。它的效果是切断 valid 和 addr_ok 之间的组合逻辑。实际上 skid buffer 类似于一个长度为 1 的队列。在 skid buffer 内部有一个缓冲区:

- 如果缓冲区不为空,发送缓冲区内的请求。否则发送流水线的请求。
- 当流水线的请求在当前周期不能发出时,可以将其缓存。
- 当内部缓冲区被占用时,流水线一侧的
addr_ok设为 0,从而阻塞流水线。 - 当缓存一侧的
addr_ok为 1 时,请求完成,可以清空内部缓存区。
这里最重要的一点是,只要内部缓存区为空(empty 信号),skid buffer 就能将流水线一侧的 addr_ok 拉起,而不用关心缓存一侧的 addr_ok 是否为 1。empty 使用一个寄存器存储。这样就能把流水线一侧的 valid 和 addr_ok 之间的组合逻辑切开。同时,我们可以看到整个过程不需要额外的时钟周期。
这里有一个参考实现:RequestBuffer.sv
*利用 WRAP 突发传输
缓存从内存读取 cache line 的时候不一定需要从 cache line 的第一个字节开始读取。利用 WRAP 突发传输,可以从 cache line 的任意位置开始读取。如果流水线访存地址的偏移量不是在 cache line 的起始位置,那么利用 WRAP 突发传输,我们可以从访存地址的偏移量处开始突发传输。那么当第一个数据从 CBus 返回时,就能直接将这个数据返回给流水线。这样流水线就不用等待整个突发传输完成了。
*非阻塞缓存(Non-Blocking Cache)
更进一步,对于正在读取的 cache line,如果访存地址的偏移量对应部分的 cache line 已经读取到了,那么可以直接返回。此时可能需要维护一个 bit 数组记录 cache line 的哪些地方已经读到了。
*后台写回
当 cache line 被写回时,可以不用阻塞住整个缓存。只要流水线访存的 cache line 还在缓存内,缓存就应该能继续服务。
实验提交
本次实验和实验 3a 一起提交。
通过标准
- 上板通过
test1、test2和test3的测试。
截止时间
2021 年 5 月 10 日 12:00
*思考题
- 文档中描述的 skid buffer 没有把流水线一侧的
valid和缓存一侧的valid之间的组合逻辑切开。你有什么改进办法能把这两个信号之间的组合逻辑切开吗?这样做会有什么代价吗? - 张三设计了一个流水线阻塞机制:相邻的流水线阶段 X 和 Y 间有一对握手信号
valid和ready。阶段 X 在阶段 Y 之前。valid表示阶段 X 已经执行完成,可以进入到阶段 Y。ready表示阶段 Y 已经执行完成,阶段 X 的数据可以进入。- 假设流水线只有最后一个阶段可能需要多个周期,其余阶段只需要一个周期。请说明最后一个阶段该如何阻塞第一个阶段的执行。这之间握手信号的延时如何?
- 如何减少上一问中握手信号的延时?
- 如果你实现了 skid buffer,请尝试模仿实验 3a 中的方式,为你的 skid buffer 编写单元测试。
实验 4:MIPS 异常与中断
参考资料: MIPS 手册 Ⅲ
异常种类
实现以下几种类型的异常:
- 读地址错和写地址错。
- 溢出、
break指令和syscall指令(Execution Exceptions)。 - 保留指令(Instruction Validity Exceptions)。
- 中断。
中断包括软件中断和硬件中断。软件中断是由软件通过执行某些指令来产生的。硬件中断包括外部的中断(CPU 的接口 ext_int)和时钟中断。MIPS 支持 6 个硬件中断和 2 个软件中断。
CP0 寄存器
为了支持中断,MIPS 添加了协处理器(coprocessor)CP0。
CP0 是一组 32 位的寄存器,用 5 位 index 和 3 位 sel 来进行索引。本实验中只需实现 sel 为 0 的一些寄存器。
需要实现的寄存器:
- BadVAddr(8 号寄存器,地址错异常时记录该虚拟地址)。
- Count(9 号寄存器,是一个计时器,每两个时钟周期加一)。
- 该寄存器是软件可写的,软件写入的优先级高于硬件自增。
- Compare(11 号寄存器,和 Count 寄存器比较以产生时钟中断)。
- 当 Compare 寄存器被设置过,且 Compare 和 Count 寄存器值相等时,产生时钟中断信号并保持。
- 当 Compare 寄存器被软件修改时,清除时钟中断信号。
- Status(12 号寄存器,记录处理器的运行状态)。
- Cause(13 号寄存器,记录最近一次异常的原因)。
- EPC(14 号寄存器,用于异常处理结束后的恢复)。
cp0.Cause 和 cp0.Status 有很多个 field,本实验中需要实现的 field 将在下文中提到,没提到的部分可实现为只读恒为 0。
CP0 寄存器不能作为算术指令的源寄存器和目的寄存器,软件需要通过 mfc0 和 mtc0 来读取或写入它们。
CP0 寄存器的写入,包括两种情况:
- 软件通过
mtc0指令写入 CP0 寄存器。需要注意 CP0 寄存器和通用寄存器不同,有些寄存器不是每一位都允许软件进行写入,手册上的R/W权限描述了各个寄存器每一位的软件读写权限。 - 硬件写入。
对于它们的优先级,请先用单周期 CPU 模型进行讨论,再思考五级流水线中的做法。
处理异常
异常的处理是由软件和硬件共同完成的。硬件主要处理异常检测与异常恢复。
异常检测
五级流水线的前四个阶段都可能产生异常,但不一定要在当个流水段就响应,可以产生一个异常使能信号,通过流水线寄存器传到 M 阶段再进行统一处理。
中断产生的条件包括:
cp0.Status.IE为 1,全局硬件中断使能为有效。cp0.Status.EXL为 0,CPU 在执行异常处理程序时,不允许中断。- 中断源产生中断(包括
ext_int[5:0],cp0.Cause.IP[7:0]和时钟中断),且对应的中断使能cp0.Status.IM[7:0]为有效。时钟中断对应的 mask 为IM[7],外部硬件中断对应的 mask 为IM[7:2]。可用以下代码来表示:interrupt_info = ({exception.ext_int, 2'b00} | cp0_cause.IP | {cp0.timer_interrupt, 7'b0}) & cp0_status.IM;。
分析中断信号与各个异常信号,只要有一个为有效,则产生异常。检测到异常后,硬件需要做以下几件事:
- 清空流水线,并把下一条指令的 PC 设置为
0xbfc00380。本实验中,这是统一的异常处理入口。 - 根据异常优先级(手册 page 55~56),得到产生异常的原因,按照手册 138 的对应关系生成异常代码
exccode,写入cp0.Cause.ExcCode。本实验需要实现的 code 包括:Int、AdEL、AdES、Sys、BP、RI、Ov。 - 如果是地址错异常,将出错的虚拟地址写入
cp0.BadVAddr。 - 如果
cp0.Status.EXL为 0,设置cp0.EPC和cp0.Cause.BD。如果产生异常的指令不在分支延迟槽中,将cp0.EPC设为该指令的 PC,并将cp0.Cause.BD设为 0;否则,将cp0.EPC设置为分支/跳转指令的 PC(即当前 PC 减 4),并将cp0.Cause.BD设为 1。 - 将
cp0.Status.EXL设置为 1。
异常恢复
软件通过 eret 指令来恢复异常。
此时,硬件需要:
- 清空流水线,并将下一条指令的 PC 置为
cp0.EPC。 cp0.Status.EXL← 0。
有些教科书上说,对于 syscall 类型的异常,当异常返回时,应该返回到下一条指令。在 MIPS 里,这件事情由软件完成(cp0.EPC 是软件可写的)。
添加指令
添加以下指令:
add、addi、sub(可能产生溢出异常)。break、syscall。mfc0、mtc0(读取/写入 CP0 寄存器)。eret。
实验提交
18307130024/
├── report/ (报告所在目录)
├── source/ (源文件所在目录)
└── verilate/ (仿真代码所在目录)
用 zip -r 18307130024.zip 18307130024/ 打包。用 unzip 18307130024.zip 检查,应在当前目录下有学号目录。
通过标准
上板通过 test1~test5,并且 make verilate 编译通过。
test4 是异常与中断的测试,仅测试了所要求的异常与软件中断。
test5 包含了十个测试,通过调整开关来执行这十个测试。test5 的默认时钟频率是 50MHz。如果生成 bit 文件时产生时序违例(比如当你的除法器是单周期实现时),请调整时钟频率至 7MHz。助教在测试时会避开时序违例。
调试建议
test5 的十个测试很难用 Vivado 的仿真进行调试,可以用 Verilator 进行调试。不像 test1~test4,测试参数为 TEST=test1 这种,测试 test5 是对每个小测试运行一次 make vsim,参数为 TEST=sha 之类,各个测试的名字在 misc/nscscc 里可以查看到。这些测试没有 trace 文件,无法直接定位到寄存器写入错误的位置,出错了只能看波形图。
你也可以用 Verilator 运行一遍 func_test 测试,它集成了 test1~test4 的全部测试。
截止时间
2021 年 5 月 17 日 12:00
挑战课题
挑战课题一共有三个方向:流水线、访存、外设。
组队规则
你可以选择单人或者两个人组队,选择一个方向做自己感兴趣的课题。
或者是 3~4 个人组队,做龙芯杯初赛高阶的内容,并且准备参加暑期龙芯杯的初赛和决赛。此时你们的工作将会涵盖三个方向。由于龙芯杯初赛晋级的规则,我们将限定有意愿参加龙芯杯的队伍不能超过 2 支。当然,你也可以选择明确不参加龙芯杯,从而不占用初赛晋级的名额。
我们鼓励单人做挑战项目的同学参加龙芯杯个人赛。但是助教们缺乏个人赛的经验,可能无法在个人赛方向上提供很好的帮助。
无论单人还是组队,都可以选取一个队名。特别是对于有意愿参加龙芯杯的队伍,比赛时需要有自己的队伍名称。每个队伍需选定一个队长,并告知助教。
组队的截止时间是 2021 年 5 月 17 日 23:59。
提交时间
挑战项目提交的截止时间为 2021 年 6 月 20 日 23:59(暂定)。
关于评分
挑战项目是期末评分的一部分。本学期挑战课题占体系结构实验部分评分的 20%1。
- 挑战项目的绝大部分分数取决于项目的工作量、研究的深度和工作的创新性。
- 你可以选择不做挑战项目,此时你这一部分的得分为 0 分。
- 期末需要提交挑战项目的代码和文档。
- 代码占评分的 80%,文档占 20%。
- 原则上,同一个队伍内的成员将获得相同的评分。
本学期体系结构部分计划占总分的 60%。即挑战课题占到总分的 12%,实验 1 至实验 4 占 48%。
附加规则
- 在最后一次实验课(6 月 7 日),队伍需要在课上做项目中期报告。
- 单人完成的挑战项目,如果助教认为你的工作有一定的创意,无论工作量,可以获得加分。
- 我们允许期末提交时进行队内匿名互评。
- 每位同学可以和助教私聊,对自己的队友投票(upvote/downvote)。Upvote 表示你认可这位队友的突出贡献,downvote 表示你认为这位队友做的不够好。
- 你可以放弃对某位队友 upvote/downvote 的机会。
- 如果你收到队友的 upvote,每个 upvote 你将获得 0.1% 的加分。
- 如果你收到队友的 downvote,助教将进行调查,届时你的评分可能和其它队员不一样。如果你收到了过多 downvote,将严重影响你的评分。
- 投票截止时间是你们队伍挑战项目提交后的 24 小时内。
- 我们允许挑战项目的评分超过 100%。
方向一:流水线性能优化
预备条件:通过
test1、test2、test3;未实现的指令 decode 为NOP。
你将升级你的流水线架构,以获取更高的性能。
通过标准
- 上板
test1、test2、test3显示两个绿灯,多次 reset 后仍显示两个绿灯。 - 上板
test5,时序无违例。
评分标准
- 上板
test5,调整开关以运行十个测试,将七段数码管读数记录在test5_score.xls中(已上传至 eLearning),得到综合性能分。
操作步骤
打开 test5 的 Vivado 工程,导入源文件后,你可以调整你的时钟频率。
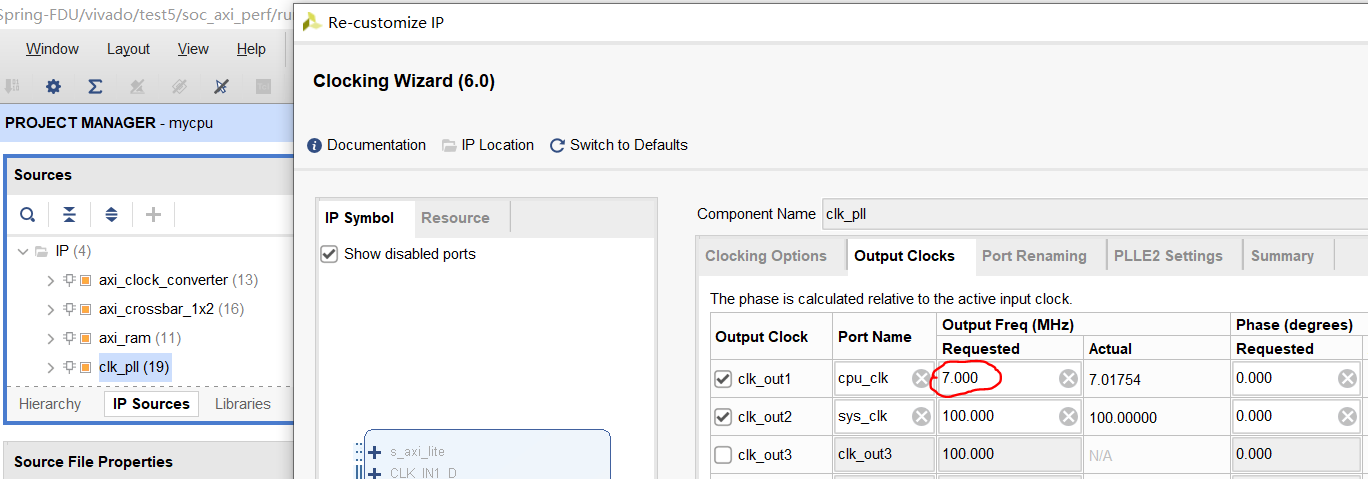
在 “IP Sources” 中,打开 clk_pll,点击 “Output Clocks”,修改 cpu_clk 的值(上图红圈的内容)为你期望的时钟频率。除了这个值,该 IP 核的其他信息均不允许修改。
生成 bit 文件后,检查是否出现时序违例:

检查上图红圈的值,不允许为负值。图中是合法值。如果出现负值,请降低你的时钟频率。如果是正值,你可以增加时钟频率,以获得更高的分数。
TIPS:如果你想知道你的 CPU 合法的最高时钟频率,请将时钟频率调整至一个非常高的值 ,确保出现时序违例。生成 bit 文件后,假设 WNS 为 ns(),那么可以通过以下公式估算最高时钟频率:
其中 单位为 MHz, 单位为 ns。
上板后,先将所有开关往下调,并把编号为 7 的开关往上调。然后,调整右侧的四个开关,让它们表示十进制数 1 到 10(对应十个测试)。

上图为 RefCPU 在 7MHz 的频率下,右侧四个开关表示十进制数 1 时的上板现象(红框处的编号为 7 的开关向上调)。七段数码管会有一个读数。如果结果为两个绿灯,则将十个测试的读数依次记录到 test5_scoce.xls(文件已上传至 eLearning,在 “实验部分” 目录下)里。如果某个测试的结果为红灯,该项成绩填 0。
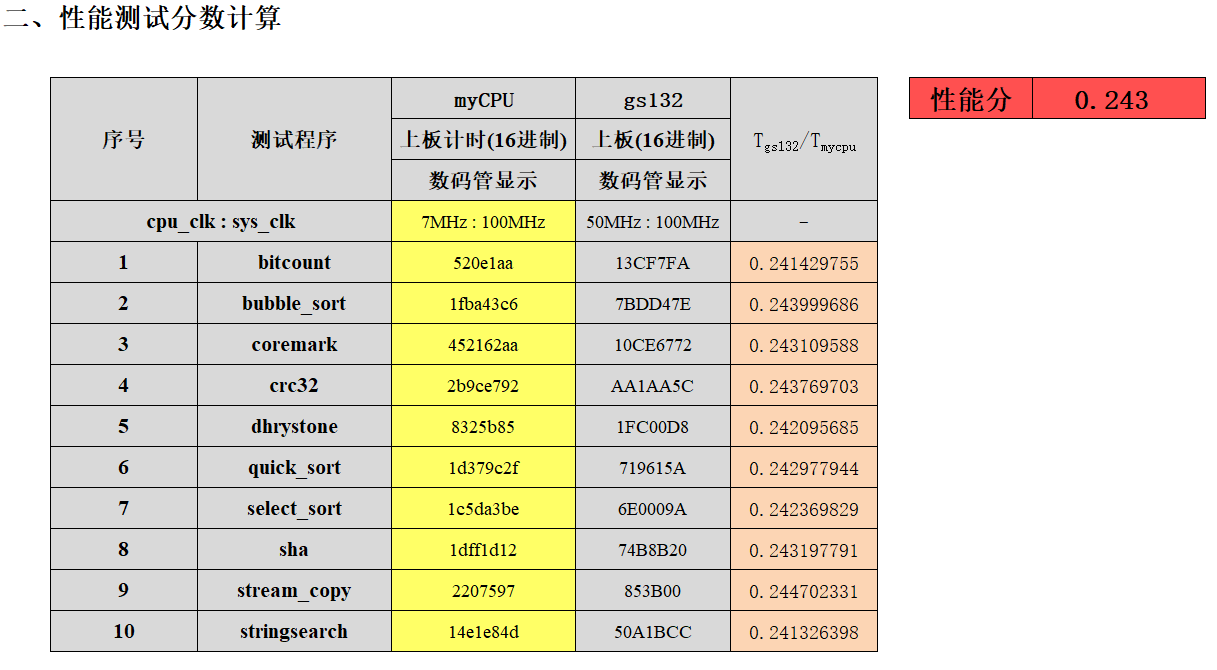
上图是 RefCPU 在 7MHz 的频率下,10 个测试的读数。填写完读数后,把表格中的时钟频率改成你 CPU 的时钟频率。图中数据所用的 bit 文件已上传至 eLearning,路径为 “实验部分/refcpu_test5.bit”。
提交内容
待定
截止时间
待定
方向二:访存性能优化
实验 3 实现了基本的 cache 后,就可以开始在访存这块挤牙膏了。
Uncached 访存
MIPS 架构中,kseg1 是 uncached 的。CPU 启动时和访存外设的时候都会从 kseg1 访问。以 UART 字符设备为例,它的访存显然是不能乱序、不能缓存、不能合并 store、不能 store 往访问同一个地址的 load 做转发的。因此 kseg1 内的访存只能按照顺序一个一个来。这极大地限制了访存的优化空间。
大多数情况下,我们还是能用 store buffer 消除掉等待 store 的 data_ok 的延时。但因为 load 不能乱序到 store 前面,因此 load 必须等待 store buffer 为空才能进行。一些乱序执行的流水线会选择把 load 也加入到 store buffer 内,这样可以同时处理多个 load/store。
问题:会有不能使用 store buffer 优化的外设吗?
ARMv8 中的内存类型和属性(memory types & attributes)
与 MIPS 相比,ARM 中的内存分类更加细致。以 ARMv8 为例,ARMv8 也使用 memory-mapped peripherals。首先内存被分为 normal memory 和 device memory。Normal memory 和大家熟知的 RAM 类似,而 device memory 一般是映射到外设的内存。
Normal memory 有 shareability 和 cacheability 两种属性。Shareability 和缓存一致性协议相关,这里不做过多讨论。Cacheability 是用来指示是否经过缓存,和 MIPS 中的 cached/uncached 类似。
Device memory 有三种属性:
- Gathering:多个 load/store 能够被合并成一次 transaction?
- Reordering:能否乱序?
- Early Write Acknowledgement:store 能否提前返回?
以上只是一个简单的介绍。有兴趣的同学可以翻阅 “Arm Architecture Reference Manual - Armv8, for Armv8-A architecture profile” 的 B2.7 小节。
问题:这些属性是怎么指定到对应的内存区域上的呢?
Cached 访存
经过 cache 的访存是优化的重点。访存性能指标主要有延时、带宽这两方面。
Pipelined Cache
当 cache 的逻辑变得复杂以后,加上大容量 cache 访存的延时,如果要求 cache 单周期返回数据可能会拉低整个 CPU 的频率。经典的解决办法就是把 cache 切成多级流水线。这样虽然增加了访存的延时,但是提高了访存并行度,从而提高了 cache 的带宽。
可以参考 2019 年龙芯杯清华队伍的三级 cache 的设计:“NSCSCC 2019 Final Report”。
Address Generation Unit (AGU)
很多乱序流水线中都有地址生成单元(AGU):
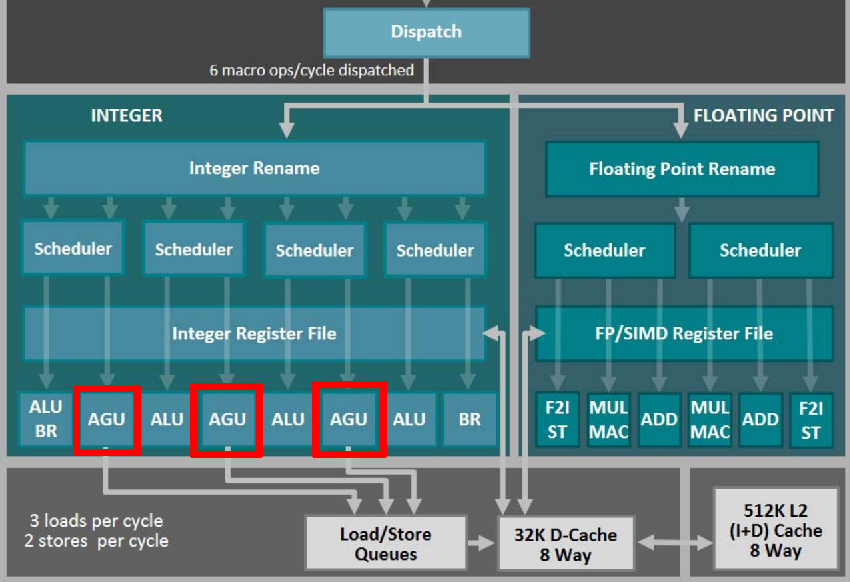
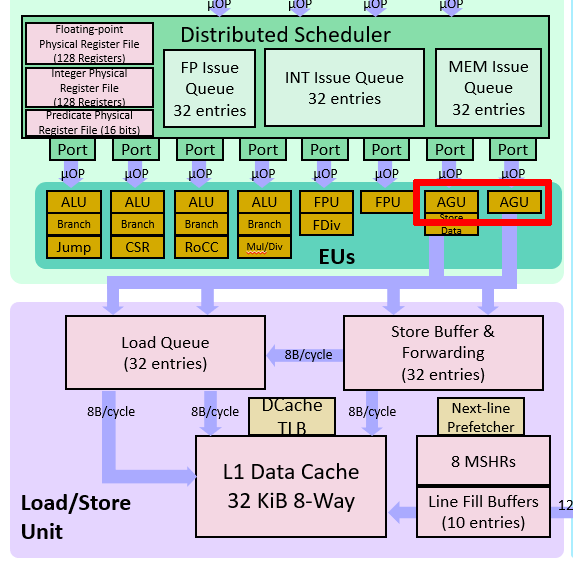
单独的 AGU 可以减轻 ALU 的计算压力。同时,这些微架构都会把 store 变成两个 μop:store-address 和 store-data。这在 Intel 的微架构图上体现得更清楚:
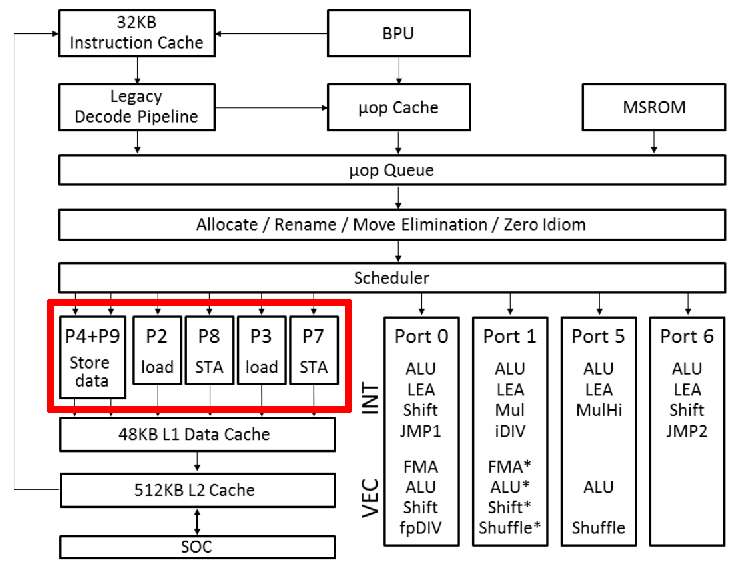
上图中 “STA” 就是 store-address。这是因为 store 需要读两个寄存器。将 store 拆成两个 μop 可以增加指令并行度。Icelake 微架构对 load、store-address 和 store-data 各有一个 buffer。特别的,如果和当前 store 相关的两个寄存器都是可以直接读取,不会造成阻塞时,Icelake 会把 store-address 和 store-data 这两个 μop “macro-fuse” 成单独的 store。
使用 LUTRAM/BRAM
在实验三中已经介绍过 LUTRAM 了。LUTRAM 和 FF 寄存器相比,更加节省 FPGA 板上的资源。我们使用的 FPGA 板上还有存储密度更大的 Block RAM(BRAM)。下面两张图对比了 256KB 的 LUTRAM 和 BRAM 板上资源的占用:
与 LUTRAM 不同的是,BRAM 需要至少一个时钟周期的延时。这和实验 1 中的情况类似。此外,因为 BRAM 在 FPGA 板上的分布比较固定,而且间距比较大,所以 BRAM 的布线延时不一定比 LUTRAM 优秀。
我们在 source/ram/BRAM.sv 中提供了一个双端口 BRAM 的封装。你也可以直接使用 Xilinx 的 xpm_memory_* 系列的 XPM 模块。XPM 模块的使用请参考:“UltraScale Architecture Libraries Guide”。
我们已经把 xpm_memory_* 模块移植到 Verilator 上了,以方便你使用 Verilator 仿真。如果你想在 Verilator 上启用 XPM 模块,请在运行 make vsim 命令的时候加上 WITH_XPM=1。由于 Xilinx 提供的 XPM 仿真模型的 SystemVerilog 代码用到了很多低版本 Verilator 不支持的语法,所以需要较高版本的 Verilator(≥ 4.108)才能成功编译。
Banked Cache
RAM 模块一般不会有很多端口。即便是 BRAM,也只会提供两个独立的端口。当多个端口同时写入同一个位置时,会发生冲突。如果没有仲裁,此时就有可能损坏数据。在仿真中,BRAM 发生读写冲突时,数据都会变成 X,以提醒你避免写冲突的出现。
为了增加 cache 的访存并行度,cache 需要提供更多的端口。一种方法是使用 banked RAM。我们可以把一条 cache line 分别存储在多个 RAM 上:

上图中,假设 cache line 大小是 64 字节。我们建立 4 个 bank,每个 bank 存储 32 位(4 字节)字宽的数据。按照交替的方式将每条 cache line 划分到四个 bank 上。如果 RAM 模块有一个读写口,那么此时相当于 cache 提供了 4 个读写口。
Bank 方式需要处理端口冲突:如果两个访存同时访问同一个 bank,需要进行仲裁。而上面之所以按照交替的方式来组织 bank,是因为减少连续读写 4 字节大小的数据时的 bank 冲突。
问题:如何快速确定访存地址对应的 bank?
问题:如果是连续读写单字节的数据(例如读写字符串),是否会有 bank 冲突?有什么缓解办法吗?
Store/Fill/Victim Buffer
为了隐藏比较耗时的操作带来的延时,往往会引入各种各样的缓冲队列。
Store buffer 早在实验 2 就已经提及了,它消除了流水线上由 store 带来的阻塞。对 cache 而言,比较耗时的事情是从主存抓取 cache line(fill)和将 cache line 写回到主存中(victim)。我们也可以用缓冲来提高 cache 的访存并发度。
例如,当某个访存未命中时,我们可以把它放入 fill buffer。之后 cache 可以继续服务其它的访存。这也就是所谓的 “hit under miss”。支持这种功能的 cache 一般称为非阻塞 cache(non-blocking cache)。同样的,如果某次访存触发了 dirty 的 cache line 的换出,我们同样可以把这个 dirty 的 cache line 放入 victim buffer,以避免其阻塞后面的访存。
这需要缓存有多个读写端口。之前的分 bank 技术已经解决了这个问题。
问题:顺序发射的流水线能否利用上 fill buffer 带来的 “hit under miss” 特性?
Early Store
当 store 操作 cache miss 时,即使新的 cache line 还没有完全从主存抓取过来,store 也是可以执行的。需要避免主存过来的数据覆盖掉已经完成的 store 的数据的情况。
Store Forwarding/Combining
和流水线上的转发类似,store 的数据可以直接转发到 store 后面的 load。
对同一个地址的连续的 store,后面的 store 数据可以直接覆盖掉前面 store 数据。有些时候可以考虑将多个小数据合并成一个大数据来写入(例如 4 个单字节的写入合并为 1 个 4 字节的写入)。
这些优化一般是由 store buffer 实现的。
Prefetch
预取(prefetch)是流水线隐藏访存延时的有力手段。目前大部分商用乱序核都有预取的能力。
预取分为硬件预取(hardware prefetch)和软件预取(software prefetch)。MIPS 架构提供了 prefetch 指令来做软件预取。
通常在 cache 空闲(比如 fill buffer 为空)时进行预取。预取需要根据之前的访存记录,判断之后访存会访问哪条 cache line。Intel 的微架构支持识别等距(stride)的访存模式,无论是顺序还是倒序,然后计算出下一次访存的 cache line。这是针对顺序访存的优化。对于乱序访存,如果 cache 发现这些访存都在某个小范围内,比如 4KB,cache 也可以考虑把这 4KB 的内存全部载入到 cache 中。
问题:众所周知,顺序访存对 cache 是非常友好的。考虑计算数组总和的 C 代码:
int sum(int n, int *a) {
int i, s = 0;
for (i = 0; i < n; i++) {
s += a[i];
}
return s;
}
请问硬件预取在 sum 函数的 for 循环中是否发挥了作用?
问题:你能举出一个使用软件预取来优化的例子吗?
自定义总线/SoC
在前几次实验中,IBus 总线宽度只有 32 位,这将成为超标量流水线的瓶颈。你完全可以自定义流水线和 cache 之间的总线,以满足流水线的性能需求。比如,你可以扩宽 IBus 总线,或者提供多个访存接口。
同样的,龙芯提供的 SoC 用的是 32 位的 AXI 总线,这也极大的限制了内存带宽。可以考虑自行修改 SoC 部分,增加 AXI 总线宽度。现代计算机的 DRAM 虽然延时很高,但是带宽也会很大。
此外,也可以考虑设计一个二级缓存,然后在一级缓存和二级缓存之间提供大带宽的总线。
Non-Temporal Access
“Non-temporal” 是程序员提供给 CPU 的 hint,表示这次访存访问到的部分在接下来的一小段时间内不会再次被访问到。例如,把矩阵初始化为全 0,很可能这个矩阵不会马上就用上。当 CPU 发现访存 cache miss 并且有这样的 hint 时,会考虑直接访问主存,而不将对应的 cache line 读取到 cache 中。这样可以避免把其它更有用的 cache line 换出。或者是给 non-temporal 的访存专门准备一个单独的 cache line,以合并连续的写入,从而能够利用主存的突发传输。
这种 hint 貌似是要有特定的指令编码的。x86 和 ARMv8 中都有专门的 non-temporal 访存指令,特别是 x86 的 SSE 指令。我暂时不知道怎么在 MIPS 中实现这种想法。
其它
由于龙芯杯的性能测试比较小,所以 32KB 的一级缓存基本上都能达到 99% 的命中率。为了能够测试出各种优化策略的效果,我们建议你使用 2KB 或者 4KB 的一级缓存来做测试和性能分析。
方向三:外设
这个方向包括两个任务:在你写的 CPU 上启动 Linux 系统,以及为外设接口编写硬件代码。
启动系统,分为两个步骤:首先是在硬件上提供 Linux 系统需要的功能,并对这些功能单独进行测试;然后是软硬件协同调试。
添加功能
你需要在硬件层面添加以下功能。
添加指令
为了启动操作系统,你的 CPU 需要支持额外的一些指令与功能:
- 算术指令:
clz、clo。 - 乘法相关指令:
mul、madd、maddu、msub、msubu。 - 非对齐访存指令:
lwl、lwr、swl、swr。- 这类指令涉及到通用寄存器的部分写(可能只写某几个字节),可选择添加字节写使能,或将寄存器原有数据和新数据拼合作为写数据。
- 条件执行指令:
movn、movz。 - TLB 类型指令:
tlbp、tlbr、tlbwi、tlbwr。tlbwr可不实现。
- Trap 类型指令:
teq、teqi、tge、tgei、tgeiu、tgeu、tlt、tlti、tltiu、tltu、tne、tnei。- 可在 E 阶段检测是否需要 trap,检测逻辑与 branch 类指令、
slt指令基本一致。注意iu后缀的立即数仍为符号位扩展。
- 可在 E 阶段检测是否需要 trap,检测逻辑与 branch 类指令、
- 缓存相关指令:
cache、pref。pref可实现为nop。
- 多核同步指令:
ll、sc、sync。ll和sc可实现为lw和sw。sync可实现为nop。
- Branch likely 指令:
beql、bgezall、bgezl、bgtzl、blezl、bltzall、btlzl、bnel。- 这部分指令可通过修改软件代码的方式去除。
- 等待中断指令:
wait。wait可实现为阻塞所有流水线,只有中断使能为高时,才跳转到异常处理程序。
支持更多异常
添加 TLB Modify (MOD)、TLB Load (TLBL)、TLB Save (TLBS)、Coprocessor Unusable (CpU)、Trap。
支持更多异常入口:
- 两个 base:
0x8000_0000、0xbfc0_0200。 - 三个 offset:
0x0、0x180、0x200。
支持更多 CP0 寄存器
- TLB 相关:Index、Random、EntryLo0、EntryLo1、EntryHi、Context、PageMask、Wired。
- Random 和 PageMask 可设计为只读为 0。
- 地址映射相关:Config。
- 缓存属性相关:Config1。
- 处理器标识:PRId (只读,reset 时复位为
32'h4220)。 - 异常相关:
- Status 的
CU、BEV域。 - Cause 的
IV、CE域。
- Status 的
TLB
Direct mapping 不能满足操作系统的需求,需要添加 TLB 地址映射机制。
在 MIPS 里,虚拟地址空间的 kseg0 和 kseg1 段通过 direct mapping 进行翻译,其它部分都需要通过 TLB 进行地址翻译。
MIPS 将 32 位的虚拟地址分成以下几个部分:
| [31:13] | 12 | [11:0] |
|---|---|---|
| virtual page number | 使用 pfn0/pfn1 | offset within page |
类似地,32 位的物理地址分为以下几个部分:
| [31:12] | [11:0] |
|---|---|
| physical page number | offset within page |
TLB 与 cache 类似。TLB 翻译的过程,就是在表中查询 virtual page number。如果命中,则转换为对应的 physical page number,否则产生一个异常。TLB 的替换算法由 CP0.Random 和软件共同维护,硬件层面无需关心。
TLB 表项的结构为:
typedef struct packed {
logic [18:0] vpn2; // virtual page number
logic [7:0] asid; // 资源拥有者标识符
logic G; // 映射是否为 global
// 以下每个属性都有两份,分别对应 vaddr[12] 为 0 或 1 两种情况
logic [19:0] pfn0, pfn1; // physical page number
logic [2:0] C0, C1; // cache flag,标识 kseg0 段是否经过 cache
logic V0, V1, D0, D1; // valid、dirty
} tlb_entry_t;
TLB 检索的代码为:
module tlb_lut (
input tlb_table_t tlb_table, // global in hardware
input word_t vaddr,
input logic [7:0] asid
);
logic [TLB_ENTRIES-1:0] hit_mask;
tlb_addr_t hit_addr;
for (genvar i=0; i<TLB_ENTRIES; i++) begin
assign hit_mask[i] = (tlb_table[i].vpn2 == vaddr[31:13]) &&
(tlb_table[i].asid == asid || tlb_table[i].G);
/* 当前进程的表项 */ /* 全局表项 */
end
always_comb begin
hit_addr = '0;
for (int i = TLB_ENTRIES - 1; i >= 0; i--) begin
if (hit_mask[i]) begin
hit_addr = i;
end
end
end
assign tlblut_resp.paddr = {
vaddr[12] ? tlb_table[hit_addr].pfn1 : tlb_table[hit_addr].pfn0,
vaddr[11:0]
};
endmodule
以上 tlb_lut 模块需要例化三个:指令请求、数据请求和 tlbp 请求。
tlbr 为读请求,用下标 CP0.Index 索引,读取整个 TLB entry。tlbp 为读请求,用 CP0.EntryHi 作为虚拟地址来查找相关信息。tlbwi 为写请求,用下标 CP0.Index 索引,将 CP0.EntryLo 等寄存器的信息写入 TLB。
TLB 有三种可能的异常:
- TLB Invalid:TLB 命中但 valid 项为 0,异常代码为
TLBL/TLBS。 - TLB Modified:在写操作中,TLB 命中,valid 项为 1, Dirty 项为 0,异常代码为
MOD。 - TLB Refill:TLB 未命中,异常代码为
TLBL/TLBS,异常 offset 为 0(可能跳转到0xbfc00200或0x80000000)。
你可以将 TLB 放在 MyCore 模块里,这样 ireq.addr 和 dreq.addr 都是物理地址;也可以放在 MyCore 外。你可以根据具体情况修改 MyCore 的接口。
龙芯杯有提供 TLB 指令与功能的测试。
cache 指令
不同进程有各自的地址空间,相同虚拟地址对应的代码可能会不同。当你运行新进程时,旧进程的指令缓存应置为无效。
操作系统使用 cache 指令来控制缓存,具体操作详见指令手册。
你可以根据具体情况修改 MyCore 的接口。
上板跑系统
当你实现了上述功能、并通过测试后,你可以上板跑系统了。
SoC
打开 SoC 的 Vivado 工程文件,将你的代码加入工程。
运行 PMon
将你的电脑和实验板用串口线连接。你可以在你的电脑上用串口软件运行控制台。
上传 Linux 内核
建立 TFTP 服务器,通过网口将 Linux 内核载入实验板。
启动 Linux
通过控制台启动 Linux。
外设接口
你也可以对实验板上的外设接口编写硬件代码。请阅读实验板外设接口部分的手册。
附加资料
这一部分包含一些与实验内容相关的资料。
外部资料
这里列举了一些和本学期实验课程以及龙芯杯相关的文档。这些资料不一定都会在本学期的实验中用到。各位同学可以根据自己的需求来翻阅。
MIPS 架构
- Volume I: Introduction to MIPS32 Architecture
- Volume II: MIPS32 Instruction Set
- Volume III: MIPS32 Privileged Resource Architecture
- MIPS 指令编码
SoC 部分
- AMBA AXI Protocol Specification v1.0
- AMBA AXI and ACE Protocol Specification
- UltraScale Architecture Libraries Guide
- BRAM & LUTRAM
2019 年龙芯杯幻灯片
2020 年龙芯杯文档
- A0 - 大赛技术方案解读
- A1 - 参赛指南
- A3 - “系统能力培养大赛” MIPS 指令系统规范
- A4 - 龙芯体系结构教学实验箱(Artix-7)介绍
- A6 - Vivado 安装说明
- A7 - Vivado 使用说明
- A8 - 交叉编译工具链安装
- A9 - CPU 仿真调试说明
- A10 - FPGA 在线调试说明
- A11 - Trace 比对机制使用说明
- A12 - 类 SRAM 接口说明
其它
- NonTrivial-MIPS
- NSCSCC 2019 Final Report
- Compiler Explorer
- “龙芯杯” 全国大学生计算机系统能力培养大赛信息汇总
- Verilator Manual
- Understanding FPGA Architecture
- GTKWave 3.3 Wave Analyzer User’s Guide
指令列表
在下表中,“✓” 表示对应测试中需要这条指令。
| 指令 | test1 | test2 | test3 | test4 | bitcount | bubble_sort | coremark | crc32 | dhrystone | quick_sort | select_sort | sha | stream_copy | stringsearch |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
addi | ✓ | |||||||||||||
addiu | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
andi | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
beq | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
bgtz | ✓ | ✓ | ✓ | ✓ | ||||||||||
blez | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
bne | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
bgez | ✓ | ✓ | ✓ | |||||||||||
bgezal | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
bltz | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
bltzal | ✓ | ✓ | ||||||||||||
eret | ✓ | |||||||||||||
mfc0 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
mtc0 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
j | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
jal | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
lb | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
lbu | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
lh | ✓ | ✓ | ✓ | |||||||||||
lhu | ✓ | ✓ | ✓ | ✓ | ||||||||||
lui | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
lw | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
ori | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
add | ✓ | |||||||||||||
addu | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
and | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
break | ✓ | |||||||||||||
div | ✓ | ✓ | ||||||||||||
divu | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
jalr | ✓ | ✓ | ✓ | |||||||||||
jr | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
mfhi | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
mflo | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||
mthi | ✓ | ✓ | ||||||||||||
mtlo | ✓ | ✓ | ||||||||||||
mult | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
multu | ✓ | ✓ | ||||||||||||
nor | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
or | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
sll | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
sllv | ✓ | |||||||||||||
slt | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
sltu | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
sra | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||||
srav | ✓ | |||||||||||||
srl | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
srlv | ✓ | |||||||||||||
sub | ✓ | |||||||||||||
subu | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
syscall | ✓ | |||||||||||||
xor | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||||||
sb | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
sh | ✓ | ✓ | ✓ | ✓ | ||||||||||
slti | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
sltiu | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |||
sw | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
xori | ✓ | ✓ | ✓ | ✓ |
了解 FPGA 架构
FPGA(Field Programmable Gate Array)是可编程逻辑阵列的缩写,我们可以在相关计算机软件的帮助下对电路板结构进行编程,来构建我们自己的集成电路板。
Vivado 中的综合阶段会将 HDL 代码转换成底层资源启用和相互连接,并在运行阶段刻入 FPGA 开发板中。
但是如果想进一步提升我们编写的硬件的性能,或多或少需要对板上的资源有一些了解。
FPGA 上的基本结构有以下几类:
- 查找表(Look-Up Table,LUT):用于实现逻辑运算。
- 触发器(Flip-Flop,FF):用于保存 LUT 的运算结果。
- 电路连接线(wires):用于连接各部件。
- IO 板块(Input/Output pads):负责 FPGA 与外部的数据交互。
这些部件可以组合出最简单的 FPGA 架构,如下图所示:
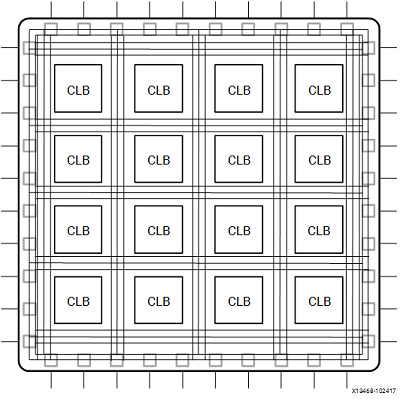
此结构尽管已经可以实现所有上层架构,但在吞吐量,资源消耗量和时钟频率等指标上有着较大的限制。
思考:这些限制来源于哪些物理因素?
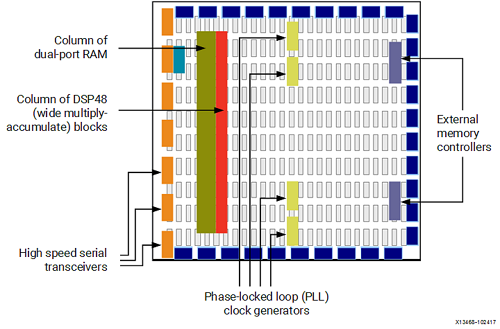
当代 FPGA 体系结构将基本部件与其他计算和数据存储模块结合在一起,从而增加了设备的计算密度和效率。
这些其他部件包括:
- 嵌入式存储器(embedded memories):用于分布式数据存储。
- 锁相环(Phase-Locked Loops,PLLs):用于以不同的时钟频率驱动 FPGA 板上的不同部件。
- 高速串行收发器(high-speed serial transceivers):利用编码技术实现高速信号传输。
- 片外存储器控制器(off-chip memory controllers)。
- 乘积块(multiply-accumulate blocks):用于加速实现 操作。
查找表(LUT)
在数字逻辑课上,查找表经常用于分支决策,但 bit 的查找表还可以看做一个映射表:
其中 为 个给定的存储单元。
通常情况下,Xilinx FPGA 内部使用 6 bit 的查找表。
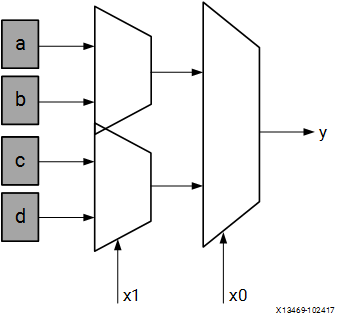
思考:一个可编程的查找表可实现 个不同的映射,为什么?
触发器(FF)
数字逻辑课上讲寄存器时,一定讲到锁存器(latch)与触发器(flip flop)。
FPGA 开发板上使用触发器作为在线存储的寄存器。
FF 寄存器最大的特点是当时钟和时钟使能均为 1 时才会锁存新的数据输入并将其输出到输出端口。
思考:为什么用触发器而不用锁存器?
DSP48 模块
在 Xilinx FPGA 最复杂的可用计算模块被称为 DSP48,如下图所示。
DSP48 模块是 FPGA 架构中的嵌入式算数逻辑单元(ALU),其计算链主要可拆分为三个阶段:
加减单元;以上一阶段结果为输入之一的乘法单元;以及最终的加/减/累加单元。
抽象地来看,它可以实现 或 这样的计算功能。
BRAM 以及其他存储器件
FPGA 开发板上具有可用作随机存取存储器(RAM),只读存储器(ROM)以及移位寄存器等的嵌入式存储元件:Block RAM(BRAM),LUT 和移位寄存器。
BRAM 是一个双端口 RAM 模块,可以提供相对较大的数据保存单元。
FPGA 开发板上有两种大小的 BRAM 存储器:18k 位 BRAM 和 36k 位 BRAM。
这些存储器的双端口性质允许对不同位置进行并行,相同时钟周期的访问。
LUTRAM 则是小型存储器,在设备配置期间(即将 bit 文件写入时)会将 LUT 真值表的内容写入其中。
我们可以利用 LUTRAM 实现不同位数的存储器,FPGA 支持在任何部分实例化 LUTRAM,可提高电路性能。

上图是一个移位存储器。
移位寄存器是相互连接的一连串寄存器,该结构的目的是沿计算路径提供数据复用。
例如,基本滤波器由一系列乘法器组成,这些乘法器将数据样本与一组系数相乘。 通过使用移位寄存器存储输入数据,内置的数据传输结构在每个时钟周期将数据样本移至链中的下一个乘法器。
LUTRAM
在实验 3 中,我们将需要大家使用 LUTRAM 编写 cache line。LUTRAM 的参考代码已经放在我们的仓库中了。
从行为级描述来看,LUTRAM 的功能十分清晰:
rview_t [NUM_WORDS - 1:0] mem = 0;
assign rdata = mem[addr];
always_ff @(posedge clk)
if (en) begin
for (int i = 0; i < NUM_WORDS; i++)
for (int j = 0; j < NUM_LANES; j++) begin
if (addr == raddr_t'(i) && strobe[j])
mem[i].lanes[j] <= wdata.lanes[j];
end
end
Verilator 仿真
在本学期的实验中,除了 Vivado 外,我们会引入 Verilator 来进行仿真。Verilator 是一个支持 Verilog/SystemVerilog 的周期精确(cycle-accurate)开源仿真器。Verilator 将用 Verilog/SystemVerilog 的 RTL 级描述的模块(module)综合为一个 C++ 模型。这个 C++ 模型一般称为 verilated model,在本学期的实验中是一个叫做 VModel 的 C++ class。然后再通过编写 C++ 代码来提供模型的输入,以及检查模型的输出。在开源领域,特别是与 RISC-V 相关的开源芯片项目,普遍使用 Verilator 进行整个 CPU 的仿真,例如中国科学院大学的 NutShell 和东京大学的 RSD。
使用 Verilator 进行仿真有两个优点。首先,仿真速度一般比 Vivado 更快。以龙芯杯性能测试中的 CoreMark 为例,在 Vivado 上仿真一次通常需要十多分钟,而在 Verilator 上只用一分钟。如果不进行波形图的记录,最快只需要 3 秒就可以完成仿真。其次,使用 C++ 编写测试相比使用 SystemVeriog 而言更具灵活性,例如我们可以很方便的在 C++ 中模拟随机访存的效果,或者是借助外部库 SDL2 将 VGA 模块的输出可视化。
Verilator 目前依然有许多不足之处。首先 Verilator 对 SystemVerilog 的语言支持还非常不完整,比如 unpacked 结构体是不支持的。此外 interface、package 这些关键字虽然支持,但是在功能上还不够完善。为了避免你的 SystemVerilog 代码不能通过 Verilator 的综合和不正确的仿真行为,请尽量避免以下事项:
- 不可综合的语法,例如延时。
initial语句。- unpacked 数组、结构体。
interface、package、class。- 小端序位标号,如
[0:31]。 - 锁存器。
logic类型的X状态和高阻抗Z状态。- 使用时钟下降沿触发。
- 异步 reset 和跨时钟域。
- 尝试屏蔽全局时钟信号。
此外,我们建议每个 SystemVerilog 文件只放一个模块,并且文件名和模块名保持一致。例如,SRLatch.sv 里面只放模块 SVLatch 的定义。更详细的内容可以参见 Verilator 手册中的 “语言限制” 一节。
综合
Verilator 只负责将 RTL 代码综合为 VModel。我们已经提供好了 make verilate 来进行综合。例如, 如果要综合 RefCPU,其顶层模块为 VTop(定义在 source/refcpu/VTop.sv 中),则可以使用下面的命令:
make verilate TARGET=refcpu/VTop
综合后的文件会放在 build 文件夹下。
如果在综合时出现错误或者警告,请按照错误消息进行修正。你需要确保你的代码没有任何错误和警告。Verilator 报告的大部分警告都是有意义的,并且 Verilator 在有警告的时候也会视为综合失败。当你发现有不太明白原因的警告时,请先查看 Verilator 手册中对于该警告的描述,确认其原因。如果你确认这个警告不会有影响,可以考虑忽略这个警告。
下面举一个实际的例子。例如,对于下面这个简单的 SR 锁存器的 Verilog 描述:
module SRLatch (
input logic S, R,
output logic Q, Qn
);
assign Q = ~(Qn | R);
assign Qn = ~(Q | S);
endmodule
将其保存到 SVLatch.sv。当我们使用 verilator --cc SVLatch.sv 命令来综合时,会得到类似于下面的警告:
%Warning-UNOPT: SRLatch.sv:3:21: Signal unoptimizable: Feedback to public clock or circular logic: 'Qn'
3 | output logic Q, Qn
| ^~
... Use "/* verilator lint_off UNOPT */" and lint_on around source to disable this message.
SRLatch.sv:3:21: Example path: Qn
SRLatch.sv:5:15: Example path: ASSIGNW
SRLatch.sv:3:18: Example path: Q
SRLatch.sv:6:15: Example path: ASSIGNW
SRLatch.sv:3:21: Example path: Qn
%Error: Exiting due to 1 warning(s)
在第一行,我们可以看到警告的类型是 UNOPT。在警告消息里面有一个对该警告的简短的描述。我们可以前往 Verilator 中 “警告和错误” 的文档搜索关于 UNOPT 的详细描述:
UNOPT
Warns that due to some construct, optimization of the specified signal or block is disabled. The construct should be cleaned up to improve simulation performance.
A less obvious case of this is when a module instantiates two submodules. Inside submodule A, signal I is input and signal O is output. Likewise in submodule B, signal O is an input and I is an output. A loop exists and a UNOPT warning will result if AI & AO both come from and go to combinatorial blocks in both submodules, even if they are unrelated always blocks. This affects performance because Verilator would have to evaluate each submodule multiple times to stabilize the signals crossing between the modules.
Ignoring this warning will only slow simulations, it will simulate correctly.
事实上就是锁存器的描述中有组合回路。可以通过在代码附近加上 /* verilator lint_off UNOPT */ 来消除 UNOPT 警告,即
/* verilator lint_off UNOPT */
assign Q = ~(Qn | R);
assign Qn = ~(Q | S);
/* verilator lint_on UNOPT */
这样上述两行 assign 就不会再报告 UNOPT 了。如果想要消除所有文件的 UNOPT 警告,需要前往 verilate/Makefile.verilate.mk 文件,在 SV_WARNINGS 变量后面添加 -Wno-UNOPT:
SV_WARNINGS = \
-Wall -Wpedantic \
-Wno-IMPORTSTAR \
-Wno-UNOPT
# add warnings that you wanna ignore.
当然,请注意在你的 SystemVerilog 代码里面应该避免组合回路而不是单纯地消除这个警告!
关于 UNOPT 警告更详细的说明,请参见 “组合逻辑环与 UNOPT”。
周期精确仿真
所谓周期精确仿真,是在确定模块输入的情况下,计算出模块在足够长时间后的输出。因此在周期精确仿真中没有延时的概念。可以理解为每次更新都是计算模块在无穷久后处于稳态时的输出。对于 CPU 这种由一个时钟信号驱动的设计,外层代码(C++ 代码)可以通过反复变动时钟信号的值(从 0 变 1,再从 1 变 0),就能得到每个周期内 CPU 的状态。
在 VModel 中,其核心的函数是 eval,它负责计算输入更新后模块的输出。如果 VModel 的时钟信号名为 clk,并且是在时钟上升沿时触发,则我们可以使用类似于下面的 C++ 代码来更新一个周期:
void tick() {
/**
* +--1--+ +--1--+ +--1--+
* A | B | A | B | A | B | A
* clk --0--+ +--0--+ +--0--+ +--0--
* ---------->|---------->|---------->|---->
* tick() tick() tick() ...
* ---------------------------------->| ...
* ticks(3)
*/
clk = 0;
// 更新内存部分的反馈
// oresp = ...
eval();
// A:此时是在时钟上升沿之前
clk = 1;
eval();
// B:此时是时钟上升沿触发后
}
具体的例子可以参见 verilate/source/refcpu/VTop/refcpu.cpp 中的 RefCPU::tick 函数的实现。
仿真框架
在本学期的实验中,我们已经提供了 Verilator 下 C++ 仿真的代码框架。代码位于 verilate/source 和 verilate/include 两个文件夹下面。仿真框架已经有内存部分和龙芯杯的 CONFREG 部分的仿真代码。你只需要按照实验文档的指示提供与你的 CPU 相关的部分的交互代码即可。仿真的命令为 make vsim。
以 RefCPU 为例,如果想要对 source/refcpu/VTop.sv 进行仿真,只需要指定 TARGET=refcpu/VTop,即
make vsim TARGET=refcpu/VTop
上面的命令将会把 verilate/source/refcpu/VTop 下的 C++ 代码连同我们提供的仿真框架一起编译,得到一个可执行文件 vmain。这个可执行文件 vmain 是放在 build 文件夹下的。之后运行 vmain 进行正式的仿真。
make vsim 命令有如下的参数:
USE_CLANG:是否使用 LLVM clang 编译?默认为0,表示使用 GNU G++ 编译。使用 Ubuntu 18.04 的同学需要指定USE_CLANG=1。VSIM_ARGS:用于指定传给可执行文件vmain的参数。例如,make vsim VSIM_ARGS='-h'可以查看vmain支持哪些参数。VSIM_OPT:是否开启编译器优化?默认为0。注意,VSIM_OPT为0的时候,由 Verilator 生成的 C++ 代码依然会开启优化。这个参数只控制我们的仿真框架的代码。VSIM_SANITIZE:是否开启编译器的 address sanitizer 和 undefined behavior sanitizer?默认为0。
为了加速 C++ 代码的编译,我们建议在 make 的时候加上 -j 选项,允许 make 多进程并行编译 C++ 代码。例如
make vsim -j TARGET=mycpu/VTop USE_CLANG=1
波形图记录
当仿真出现问题时,我们可以使用输出调试和 GDB 来寻找出错的原因。但是这对于 SystemVerilog 代码的调试并不方便,此时我们可能需要波形图来方便调试。
make vsim 在默认情况下不会记录波形图。仿真程序 vmain 是支持记录波形图的。可以用 --fst-trace/-f 选项来指定保存波形图文件的位置。例如
make vsim VSIM_ARGS='-f build/trace.fst'
将会把波形图保存到当前目录下的 build 文件夹中,波形图文件名为 trace.fst。之后我们可以使用 GTKWave 来查看 FST 格式的波形图。
请注意,开启波形图记录后的仿真速度大约会慢 10 倍。
组合逻辑环与 UNOPT
上一节中的 SRLatch 是一个典型的组合逻辑环的例子。在 Vivado 中,SRLatch 可以综合和布线,但是布线阶段 Vivado 也会警告代码中的组合逻辑环:

因为组合逻辑环容易导致电路振荡,从而造成 “仿真通过但上板不过” 的情况。因此,请务必消除 Vivado 报告的组合逻辑环。
Verilator 对于组合逻辑环通常报告 UNOPT 或者 UNOPTFLAT 警告,字面意思是不好优化,因为组合逻辑环需要多次迭代后才能得到最终的结果(收敛)。这两种警告的区别在于,一个是 Verilator 生成网表(flatten netlist)前报告的,一个是生成网表后报告的,因此这两种警告对我们而言没有区别。下文中两种警告都用 UNOPT 指代。
Verilator 虽然声称忽略这些警告不会影响仿真的正确性,只会影响仿真的性能。但我们的 CPU 中不应该有组合逻辑环。如果有,大概率是有地方写错了,导致仿真的结果和我们的预期不符。根据我们的经验,大家在写流水线的 hazard 部分时比较容易写出组合逻辑环。
对于 Verilator 报告的 UNOPT 警告,某些情况下不一定是真的组合逻辑环。这是因为,出于仿真性能上的考虑,Verilator 并不是按信号的每一位来单独计算的,通常会把很多信号放一起计算(比如都放在一个 uint32_t 内)。你可以简单地认为 Verilator 是在变量层级生成网表。下面将举几个常见的例子。
例子:StructWire
module StructWire (
input logic a,
output logic d
);
struct packed {
logic b, c;
} block;
assign block.b = a;
assign block.c = block.b;
assign d = block.c;
endmodule
这段代码单纯地把 a 的值传给 d,中间经过了 block。很明显,a → block.b → block.c → d 没有形成组合逻辑环,但是 Verilator 会把 block 这个变量看作一个整体,于是就出现了 block → block 这个假的逻辑环。此时你只需使用 /* verilator split_var */ 来消除警告:
struct packed {
logic b, c;
} block /* verilator split_var */;
split_var 告诉 Verilator 要把 block 拆成多个变量(可能是 block__DOT__a 和 block__DOT__b 之类的)。这样一来 Verilator 就不会报告 UNOPT 了。
注意:
/* verilator split_var */需要 Verilator 的版本 ≥ 4.0301。如果你用的是 Ubuntu 20.04,那你有可能在使用 4.028。请按照课程仓库首页的指示安装较新版本的 Verilator。我们在测试的时候会使用较高版本的 Verilator。
例子:PartialSum
下面是一个异或前缀和的例子:
module PartialSum (
input logic [31:0] a,
output logic [31:0] b
);
assign b[0] = a[0];
for (genvar i = 1; i < 32; i++) begin
assign b[i] = b[i - 1] ^ a[i];
end
endmodule
和 StructWire 一样,从每一位来看,不存在逻辑环。但是 Verilator 会认为有 b → b 的组合逻辑环。所以这里也需要将 b 的每一位分开。但与 StructWire 例子中不一样的是,b 是模块的端口,如果你尝试:
module PartialSum (
input logic [31:0] a,
output logic [31:0] b /* verilator split_var */
);
你会收到下面的警告:
%Warning-SPLITVAR: PartialSum-SPLITVAR.sv:3:25: 'b' has split_var metacomment but will not be split because it is public
3 | output logic [31:0] b /*verilator split_var*/
| ^
... Use "/* verilator lint_off SPLITVAR */" and lint_on around source to disable this message.
%Error: Exiting due to 1 warning(s)
因为 b 是公开的模块端口,所以 Verilator 拒绝直接将 b 分为多个变量。一个常用的技巧是引入一个私有的中间变量:
logic [31:0] c /* verilator split_var */; // 引入中间变量
// 对 c 而不是 b 做操作
assign c[0] = a[0];
for (genvar i = 1; i < 32; i++) begin
assign c[i] = c[i - 1] ^ a[i];
end
assign b = c; // 再将 c 整体赋值给 b
例子:AlwaysComb
下面这个例子来自某位同学实验 1 的代码。我们对原始代码做了简化,大致的代码结构如下:
module AlwaysComb (
input logic a, d,
output logic c, f
);
always_comb begin
// ...
f = ~a;
// ...
c = d ^ f;
// ...
end
endmodule
module Top (
input logic a, b,
output logic c
);
logic d, f;
assign d = b ^ f;
AlwaysComb inst(.*);
endmodule
将上面的代码画成原理图,并没有发现逻辑环:

但是 Verilator 依然会报告 UNOPT。这是因为 Verilator 把 always_comb 语句块作为一个整体处理。Verilator 认为上面的 always_comb 块的输入(敏感列表)有 a、d 和 f,输出有 c 和 f。因此,当 a 发生变化时,触发 always_comb 块,从而 f 也会发生变化。然后 d 也发生变化。由于 d 是 always_comb 块的输入之一,导致 Verilator 认为形成了 f → d → f 的逻辑环。但是明显 d 的变化不会导致 f 变化。消除这个 UNOPT 的一种方法就是将 always_comb 一分为二:
always_comb begin
// ...
f = ~a;
// ...
end
always_comb begin
// ...
c = d ^ f;
// ...
end
事实上这种拆分无论是对 Verilator 还是对一般的事件驱动的仿真器都是有好处的,因为拆分后可以减少不必要的迭代,从而优化仿真性能。从这个例子中可以总结出一个经验:always 块应该避免给变量赋值后使用这个变量,也就是避免变量同时出现在 always 块的输入和输出中。同时我们也鼓励大家不要写过长的 always 块,而是尽量将其分为若干个独立的 always 块。
例子:Box
下面这段代码中有一个真的组合逻辑环,和一个假的组合逻辑环。请尝试用 verilator --lint-only [文件名] 找出这两个逻辑环。
typedef logic [31:0] i32;
typedef struct packed {
logic valid, write_en;
i32 addr, data;
} req_t;
typedef struct packed {
logic data_ok;
i32 data;
} resp_t;
module Box (
input logic clk, resetn,
input req_t req,
output resp_t resp
);
i32 stored;
assign resp.data_ok = req.valid && req.addr == 32'h19260817;
always_comb begin
if (resp.data_ok)
resp.data = stored;
else
resp.data = '0;
end
always_ff @(posedge clk)
if (resetn) begin
if (req.write_en)
stored <= resp.data_ok ? req.data : stored;
end else
stored <= 32'hdeadbeef;
endmodule
module Fetch (
input logic flush,
output req_t req,
input resp_t resp
);
assign {req.valid, req.addr} = {!flush, 32'h19260817};
endmodule
module Core(input logic clk, resetn);
logic flush /* verilator public_flat_rd */;
req_t req /* verilator public_flat_rd */;
resp_t resp /* verilator public_flat_rd */;
assign flush = resp.data_ok && resp.data == '0;
Fetch trump(.*);
Box biden(.*);
endmodule
使用 GTKWave
打开样例波形图文件:
gtkwave misc/demo.fst
一开始面板上是没有信号的。另外有一个文件 misc/demo.gtkw 是与之相关联的配置文件,也可以直接打开:
gtkwave misc/demo.gtkw
添加信号
当你想加入更多的信号时,点击主菜单中的 “Search” → “Signal Search Tree”(或者使用快捷键 Shift+Alt+T 呼出)。之后会看到下面的窗口:
(这个窗口貌似有 BUG,第一次打开后关掉再重开,就展开不了结构树了...)
你也可以用 “Search” → “Signal Search Regexp” 来用文本搜索信号名。
生成新的波形图
我们的 Verilator 仿真程序一般支持使用 --fst-tract/-f 参数来指定 FST 波形图保存的位置。例如:
make vsim -j VSIM_ARGS="-f ./build/trace.fst"
将会在 build 目录下生成一个名为 trace.fst 的波形图文件。之后可以直接用 GTKWave 打开。
配置
开学在寝室无所事事?请阅读 GTKWave 用户手册: GTKWave 3.3 Wave Analyzer User’s Guide。
不想折腾?请将下面的内容写入 ~/.gtkwaverc:
# 选择字体
#fontname_signals Lato 16
#fontname_logfile Lato 16
#fontname_waves JetBrains Mono Medium 14
# 快捷键
# “x” 新建一个 marker,“z” 删除一个 marker,“c” 删除所有 marker
accel "/Markers/Drop Named Marker" x
accel "/Markers/Collect Named Marker" z
accel "/Markers/Collect All Named Markers" c
fill_waveform 1
hide_sst 1
hier_grouping 1
hier_max_level 2
left_justify_sigs 1
use_fat_lines 1
use_roundcaps 1
wave_scrolling 1
disable_mouseover 0
highlight_wavewindow 1
splash_disable 1
color_back 041933
color_0 54c231
color_1 54c231
color_vbox 54c231
color_grid 666666
color_trans cc0000
color_vtrans cc0000
color_value eeeeee
color_umark f9fd01
enable_horiz_grid 0
page_divisor 4
示例
(上面演示中使用的是 GTK3 版本的 GTKWave)
为什么要用 GTKWave?
GTKWave 看起来挺土的,而且貌似有很多 BUG...
因为没有其它软件了。开源的波形图浏览器只有这一个能打的 :)
仓库目录结构
为了方便大家了解和浏览整个 Git 仓库,这里提供一个对仓库中目录结构和文件的说明。
build
build 文件夹下用于放置编译后的文件,包括 Verilator 的综合结果和 C++ 编译过程中的生成物以及最终的可执行文件。这个文件夹下有一个 .gitkeep 文件,用于确保 Git 会记录这个文件夹。使用 make clean 命令会清空 build 文件夹。
根据 Make 的参数,编译过程中会在 build 文件夹下建立不同的子目录。例如 build/gcc+optimized 表示使用 GNU G++ 编译并且参数 VSIM_OPT=1(开启编译优化),而 build/clang+sanitizer 表示使用 LLVM clang 编译(USE_CLANG=1)并且参数 VSIM_SANITZE=1。具体的规则参见文件 Makefile 中变量 BUILD_ROOT 的设置。
doc
本学期实验的所有文档都位于此目录下。doc/src 内是文档的原始 Markdown 文件,doc/book 是使用 mdBook 编译后得到的网页文件。文档中使用的图片均放在 doc/src/asset 目录下。
misc
放置各种各样的资源文件,比如测试的内存加载文件(.coe)。龙芯杯的性能测试的内存文件放在 misc/nscscc 目录下,以方便 Verilator 仿真。
source
RTL 源代码所在的文件夹。
source/include
所有的 SystemVerilog 头文件(.svh)都放在这个文件下。source/include/common.svh 内包含一些通用的定义。source/include/refcpu 下放的是和 RefCPU 相关的头文件。如果你需要使用头文件,可以放在 source/include/mycpu 目录下。
source/mycpu
你的 SystemVerilog 源代码文件夹。这个文件夹一开始已经包含了一些模块的定义和实现:
add_sources.tcl:用于将你的 CPU 的源代码加入到 Vivado 工程中的 Tcl 脚本。DCache.sv、ICache.sv:数据缓存和指令缓存。这两个文件会在实验 3 的时候用到。一开始是直接用数据缓存当指令缓存用,并没有分别实现。MyArbiter.sv:你的访存仲裁器。这个文件将会在实验 2 用到。MyCore.sv:你的流水线部分。MyCore这个模块一共有 6 个接口:clk、resetn、ireq、iresp、dreq、dresp,分别表示时钟信号、复位信号、指令访存请求、指令访存回复、数据访存请求和数据访存回复。其中指令访存和数据访存涉及到的结构体的定义都位于source/include/common.svh中。mycpu_top.sv:接入龙芯杯的测试的顶层模块。SRAMTop.sv:使用类 SRAM 接口时 CPU 的顶层模块。VTop.sv:使用 AXI 接口时或者进行 Verilator 仿真时 CPU 的顶层模块。VCacheTop.sv:测试缓存时的顶层模块。
source/refcpu
RefCPU 的源代码。目录结构和 source/mycpu 是类似的。
source/ram
存放 BRAM 和 LUTRAM 模块和它们的测试文件。
source/util
我们提供的辅助模块,主要是各种总线之间的转接桥。其中 CBusArbiter.sv 是我们提供的仲裁器的实现。你可以直接使用 CBusArbiter 而不需要实现自己的仲裁器 MyArbiter。
verilate
用于存放 Verilator 仿真时用到的 C++ 代码。verilate/include 是共用的 C++ 头文件,verilate/source 下是所有的 C++ 代码。直接放在 verilate/source 目录下的是通用的 C++ 代码。针对不同的模块的测试,专用的代码会放在这个文件夹的子目录下。例如 verilate/source/refcpu/VTop 就是用于存放测试 source/refcpu/VTop.sv 这个顶层模块的所有 C++ 代码。
在执行 make vsim 命令时,参数 TARGET 可以指定编译哪个顶层模块对应的 C++ 代码。默认 TARGET=refcpu/VTop,即编译 verilate/source/refcpu/VTop 下的代码。编译后的可执行文件名为 vmain,会放到 build 文件夹下的对应位置,例如 build/gcc/refcpu/VTop/vmain。
vivado
用于存放龙芯杯的测试。龙芯杯的功能测试被分为了测试 1 至测试 4,分别放在 vivado/test1 到 vivado/test4 这四个目录下。vivado/test1_naive 的测试内容和 vivado/test1 的测试内容相同,只有顶层使用的接口不同。vivado/test5 是龙芯杯的所有性能测试。此外除了 vivado/test1_naive 使用固定延时的类 SRAM 接口外,其余测试使用的都是有随机延时的 AXI 接口。
Vivado 的工程文件(.xpr)通常放在名为 run_vivado 的文件夹下,例如 vivado/test1/soc_axi_func/run_vivado/mycpu_prj1/mycpu.xpr。可以使用 Vivado 直接打开这个工程文件。如果某个测试需要建立多个工程,请注意复制对应的文件夹后再用 Vivado 打开。
常见问题
关于实验内容的答疑,请前往 FDUCSLG 的 Slack 平台的 #sig-architecture 频道提问。如果你不想公开提问,可以单独询问助教。
本页面不定期更新。
为什么运行 make vsim 显示 “COE file should begin with "memory_initialization_radix = "”?
请检查 misc/nscscc 目录下的 .coe 文件内容是否正确。它们都是 Linux 软链接,正常情况下,可以使用 ls -l misc/nscscc 查看到软链接到位置:
$ ls -l misc/nscscc
total 3400
lrwxrwxrwx 1 riteme riteme 58 Feb 27 12:55 bitcount.coe -> ../../vivado/test5/soft/perf_func/obj/bitcount/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 61 Feb 27 12:55 bubble_sort.coe -> ../../vivado/test5/soft/perf_func/obj/bubble_sort/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 58 Feb 27 12:56 coremark.coe -> ../../vivado/test5/soft/perf_func/obj/coremark/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 55 Feb 27 12:56 crc32.coe -> ../../vivado/test5/soft/perf_func/obj/crc32/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 59 Feb 27 12:56 dhrystone.coe -> ../../vivado/test5/soft/perf_func/obj/dhrystone/axi_ram.coe
-rwxr-xr-x 1 riteme riteme 1299476 Feb 20 12:07 func_test.coe
-rw-r--r-- 1 riteme riteme 2157055 Feb 20 12:07 func_test.txt
lrwxrwxrwx 1 riteme riteme 60 Feb 27 12:57 quick_sort.coe -> ../../vivado/test5/soft/perf_func/obj/quick_sort/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 61 Feb 27 12:57 select_sort.coe -> ../../vivado/test5/soft/perf_func/obj/select_sort/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 53 Feb 27 12:57 sha.coe -> ../../vivado/test5/soft/perf_func/obj/sha/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 61 Feb 27 12:57 stream_copy.coe -> ../../vivado/test5/soft/perf_func/obj/stream_copy/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 62 Feb 27 12:58 stringsearch.coe -> ../../vivado/test5/soft/perf_func/obj/stringsearch/axi_ram.coe
lrwxrwxrwx 1 riteme riteme 45 Mar 19 23:27 test1.coe -> ../../vivado/test1/soft/func/obj/inst_ram.coe
lrwxrwxrwx 1 riteme riteme 35 Mar 19 23:27 test1.txt -> ../../vivado/test1/golden_trace.txt
lrwxrwxrwx 1 riteme riteme 45 Mar 19 23:27 test2.coe -> ../../vivado/test2/soft/func/obj/inst_ram.coe
lrwxrwxrwx 1 riteme riteme 35 Mar 19 23:27 test2.txt -> ../../vivado/test2/golden_trace.txt
lrwxrwxrwx 1 riteme riteme 45 Mar 19 23:27 test3.coe -> ../../vivado/test3/soft/func/obj/inst_ram.coe
lrwxrwxrwx 1 riteme riteme 35 Mar 19 23:27 test3.txt -> ../../vivado/test3/golden_trace.txt
lrwxrwxrwx 1 riteme riteme 45 Mar 19 23:27 test4.coe -> ../../vivado/test4/soft/func/obj/inst_ram.coe
如果你的输出没有显示链接到 vivado 目录,说明你有可能是在非 *nix 环境下(比如 Windows)做的 git clone。你可以尝试重新 clone,或者直接在 VSIM_ARGS 中手动指定 -m 和 -r 参数。
为什么编译时报错 “undefined reference to ...”?
一般是我们更新了代码后会出现这种问题。你可以尝试先 make clean 后再重新编译。
为什么 Verilator 会报告 UNOPT/UNOPTFLAT?
这是因为你的代码中可能存在组合逻辑环。请根据 Verilator 输出的文件位置检查是否真的有逻辑环。
如果你认为并不存在逻辑环,并且 Vivado 布线时也没有报告逻辑环,有可能是遇到了 “组合逻辑环与 UNOPT” 中提到的情形。
为什么仿真一直在跑却没有显示 “Functional Test Point PASS!!!”?
有时候你甚至会发现第一个点已经显示通过了,但是第二个点的 “PASS!!!” 一直没有出现。这种情况可能是你的流水线 writeback 阶段没有写入寄存器,导致 trace 没有进行比对,因此也没有发现你 CPU 的错误。
龙芯的测试是在信号 debug_wb_rf_wen 不为零的时钟上升沿进行比对。你在仿真的时候可以注意下波形图中 debug_wb_rf_wen 这一行是否出现了 4'hf,如果出现了则说明 trace 比对正在进行。如果全程为 0 则说明你的流水线没有写入寄存器,或者是 debug_* 信号连接出错。
为什么 Vivado 上的仿真非常慢?要跑十多分钟甚至是一个小时?
我们提供的测试的设置中,默认是会在仿真过程中记录所有的信号。这样在测试不通过时,可以查看所有的信号来寻找问题,方便大家调试。由于 Vivado 自带的 xsim 仿真器本身性能不高,如果需要记录所有的信号,势必会严重拖慢仿真。如果你想加快仿真速度,可以考虑关闭完整的信号记录。
依次点击 Vivado 顶部菜单栏的 “Tools” → “Settings...”,然后在下图所示的窗口中按照红色矩形框的指示,将 xsim.simulate.log_all_signals 右侧的勾选框取消。
然后点击 “OK” 保存设置。之后重新启动仿真。
我能拿 A 吗?
未来可期。
可以退课吗?
耗子尾汁。
这课保 B+ 吗?
无可奉告。
贡献者
- 谭一凡(@Tan-YiFan)
- 薛振梁(@riteme)
- 彭润宇(@Pryest)
- 韩晓宇(@HatsuneHan)
Powered by mdBook.